The AI Code Verification Bottleneck: Why Faster Code Generation Means Slower Reviews

According to the State of Code Developer Survey, AI now writes 42% of committed code. You’d think that would reduce review time by a healthy margin, but new research and personal experience show the opposite. Review cycles are taking ages and getting dragged out.
AI-assisted development is designed to get you to production faster. And to be fair, that’s true to an extent. Developers are generating more code, opening more PRs, and, by an extension, shipping more quickly. But here’s the catch: when you ship faster, you also fail faster. Faros AI conducted analyzed data from 10,000 developers and found that while teams with high AI adoption merge 98% more pull requests, PR review time increases by 91%. That’s a very interesting (and telling) piece of information!
TL;DR The math just isn’t mathing. AI is generating code much faster than a review process that still relies mostly on humans can keep up with. The answer probably isn’t faster reviews, but changing where the verification occurs. In this easy-to-digest, hands-on article, I will cover the intricacies behind this bottleneck and what it all looks like in practice.
The Math Problem
How many LOC can a senior dev meaningfully review in an hour? 100? 200? Let’s say the baseline assumption is 150.
Now let’s compare that to an AI-assisted developer.
AI doesn’t operate in lines per hour, but in files per minute, which is a completely different scope of measurement. An AI agent can produce 500 to 2,000 lines of structured code in a quick session. During that period, a dev has not even finished a standup.
When that AI-powered PR hits a review queue, someone has to process it. And that “someone” almost always refers to a senior engineer, as juniors typically don’t have the context to catch what matters.
The math here compounds pretty damn fast. One AI-assisted developer generating three or four PRs per day creates a review load that previously would have required a few engineers worth of resources. Scale that across a team of ten developers all using AI tools, and the queue becomes unmanageable without increasing reviewer headcount proportionally, which defeats the efficiency argument.
Faros AI’s report backs this up. According to it, AI adoption is associated with a 154% increase in average PR size. And it’s not just more PRs, but bigger ones, as well.
Reviewing a 600-line diff is not in the same league as reviewing 150 lines. The reviewer is basically reading an unfamiliar module from scratch while being expected to approve or reject the PR with a clear, well-supported explanation. Not an easy task, I’ll tell you that.
What the Bottleneck Looks Like in Practice

A rapid unscheduled dissasembly
A bottleneck will not result in a dramatic failure, but quietly accumulating friction will.
Senior engineers are the only ones with enough context and expertise for high-value tasks: business logic, architectural decisions, and undocumented shenanigans from lord knows how many years ago. Their queue fills up fast while PRs sit, waiting.
At the same time, review quality drops as volume increases. A senior reviewing their eighth PR of the day is not operating at the same brain frequency as when they were on their first. Code generation is 10x faster but reviews stay at a constant velocity.
And there you have it, Amdahl’s Law in practice: the queue becomes the limiting factor.
None of this results in a production outage. It just adds days upon days to cycle time. That’s why it’s so easy to miss until you’re already knee-deep in hot water.
Why “Review Faster” Isn’t the Answer
The logic would lead us to add more reviewers or to automate a larger portion of the review process. Unfortunately, none of this helps the root problem.
More reviewers just add people cost, which cancels out the efficiency gain AI was supposed to bring. It also doesn’t solve the context problem. A reviewer who isn’t deeply familiarized with the code can catch style issues but not intent issues, which is exactly what AI-generated code tends to get wrong.
Automated review tools help at the margins. They catch the stuff they are designed to catch: vulnerabilities, style violations, or test coverage gaps. But as we’ve covered in the previous article in this series, an automated review has a structural ceiling. Automation cannot verify intent, and it cannot check the code against what the spec actually says.
What Intent-Driven Verification Changes
The rhetoric should be changed from “Does this code look right?” to “Does this code do what it was supposed to do?”
These are fundamentally different questions with different verification methods.
“Does this code look right?” requires a human to read the diff, hold the codebase in their head, and make a judgment call. In short, it doesn’t scale with volume because it depends entirely on human cognitive bandwidth.
“Does this code do what it was supposed to do?” can be answered deterministically but only if the “what it was supposed to do” part has been written down before the implementation started. And that’s the spec.
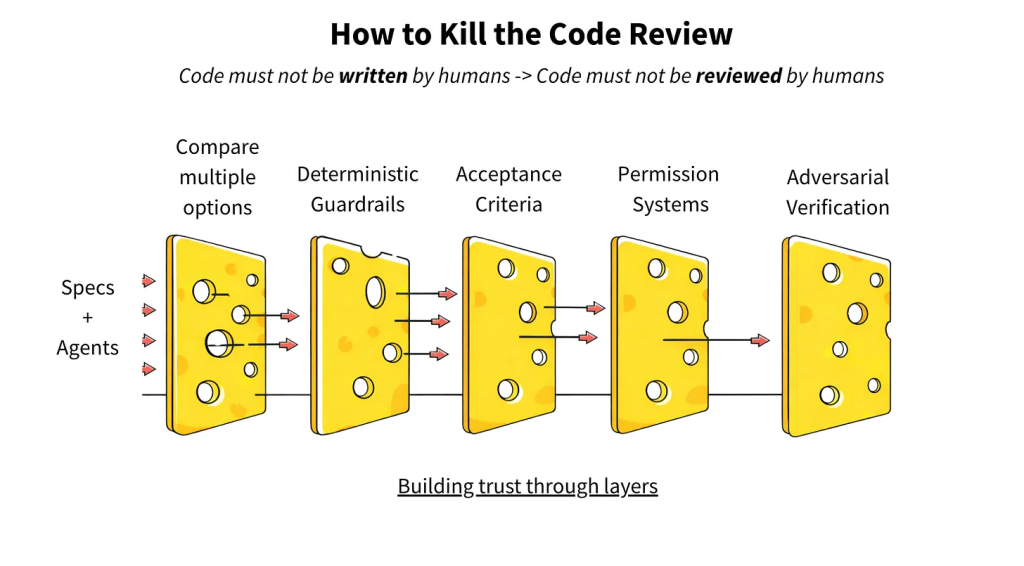
Verify checks the implementation against the spec across three layers:
- Org invariants catch the non-negotiables that apply everywhere. No hardcoded secrets, auth on every endpoint, and such.
- Domain contracts apply to specific parts of the codebase. The billing module uses the
Moneytype, and the payments domain emits events for every state change. - Acceptance criteria are specific to the change. The endpoint exists, returns the right fields, and returns 404 when the subscription doesn’t exist.
This is the Swiss cheese model. A single layer will not catch everything, obviously, but all of them together will cover the gaps.
Aviator ran a real-world experiment with 6,000 lines of AI-generated code that were checked against 65 acceptance criteria in 6 minutes. 60 passed, 4 failed, 1 partial. A human doing the same work would have taken hours and would have done it only once.
If a spec exists as a human-approved artifact with explicit acceptance criteria, the implementation can be checked against it programmatically (through AST parsing, execution tests, and pattern analysis run against each criterion).
Next Steps

AI reviewing AI
AI reviewing AI-generated code is a bit like this Obama meme. Technically a review did happen, but nobody independent had a say in the whole process.
On top of that, bigger PRs equal more cognitive load, and the human brain has its own token limit. Unlike Claude, it does not reset cleanly. It just starts missing things. ☹️
The positive side is that you don’t need something revolutionary. Most devs are already somewhere in the middle: not reading every line, but not fully trusting AI either. The shift that helps is moving the human judgement upstream (to the spec, before implementation) and letting tooling handle the rest.
FlexReview Inbox ensures review attention stays organized so that nothing goes unnoticed. MergeQueue keeps merging safe at volume. And Aviator Verify, closes the last gap: deterministic checks against a spec a human has signed off on, before any code is written.

FAQ
1. Isn’t this just a scaling problem? Why don’t you simply hire more reviewers?
Headcount doesn’t fix the context problem. A reviewer who doesn’t know the codebase deeply can catch style issues but not intent issues, which is exactly what AI-generated code gets wrong most of the time.
2. If AI generates the code and another AI verifies it, have you just moved the problem?
Deterministic verification isn’t AI reviewing AI. It’s checking code against a human-approved spec that exists before implementation starts.
3. How do you write specs fast enough to keep up with AI-generated code?
Specs don’t have to be long. A few well-defined acceptance criteria per ticket reviewed by one other person is enough to break the circular trust loop and give verification something real to check against.
4. What if the spec is wrong?
Then you catch it before implementation, not after. The spec review is where intent errors get fixed.
5. How is this different from a static analysis, tests, or a plain AI code review?
A static analysis catches syntax and patterns. Tests verify behavior under specific input criteria, but only to the extent that the test author has thought to cover. An AI code review reads the diff and leaves comments, with no intent and audit trail. Verify is the only one with an external reference point: the spec a human has approved.


