AI Code Review Is Still a Review

If you use AI to write code, you might be tempted to let AI review it too. It could be particularly neat in an agentic workflow. One agent creates a PR, and another one scans for issues. Then the first one fixes these issue, and the third one merges the rest. This sounds like efficiency personified and, of course, decreases the time necessary to ship a feature.
Everything is running, code looks fine from a distance, reviews are passing… And yet, the system is still doing something wrong.
So, the question is, who oversees these agents?
TL;DR In this article I’ll go over the AI code review problem. These reviews can be genuinely helpful, but there are structural limitations to AI agents reviewing AI-generated code (AI inception, if you will). Humans need to jump in, and the right architecture will make this collaboration a breeze. Let’s see how you can keep your team happy. 👇
The Circular Trust Problem
Automated review tools can be divided into two categories:
- Purpose-built scanners (tools like Snyk and Semgrep)
- LLM-based review agents (tools like CodeRabbit and GitHub Copilot’s code review)
They are also genuinely good at dealing with a specific class of problems:
- Syntax and style consistency: Does the code follow the formatting and linting conventions? Does the PR introduce linting violations?
- Vulnerability patterns: A static analysis can reliably catch things like SQL injection points, hardcoded secrets, insecure defaults, dependency CVEs, and much more.
- Surface-level logic errors: An AI review can catch missing null checks, type mismatches, and random logic errors.
- Test coverage signals: Is the new code covered by tests?
All these problems are worth catching, and automated reviews are far from useless. The issue occurs when your team starts to assume that what it has covered is correct and decides to skip manual reviews, though they are objectively needed.
LLMs, for instance, are just good statistical models. In a nutshell, they predict what comes next based on the previous input and the data they’ve been trained on. As such, they are great at patterns, and while that pattern-matching can seem surprisingly smart, it has its limits. Certain gaps can be filled with the most plausible-looking answer, even though it’s wrong.
Based on these patterns in training data, models develop strong opinions on what “correct” code looks like. So, when AI-generated code is evaluated, both the code-generating agent and reviewing agent use the same corpus, the same pattern vocabulary, and the same assumptions about what valid code looks like.
This applies most directly when the same model generates and reviews the code, but the problem persists even across different LLMs.
The patterns become a closed loop with no exit point touching the original spec requirements.
We have numbers to back this up. Qodo’s 2025 research found that 65% of developers consider missing context the biggest problem with AI-generated code, ranking it above hallucinations. Meanwhile, a CodeRabbit report showed PRs per author went up 20%, but production incidents per PR increased by 23.5%. Faster shipping led to more breakage.
There’s academic backing as to why this happens. A 2025 paper on multi-agent pipelines describes this as the “popularity trap”: models trained on similar data tend to converge on the same wrong answer. Consensus starts to look like correctness, even though it’s not the same thing.
Anyway, enough with the numbers.
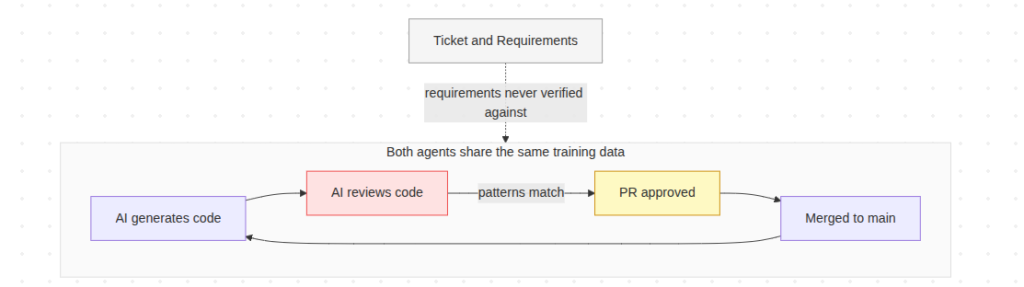
The loop that never asks if the code was right, only if it looks right
Pattern-matching is also not the same as requirements-matching. Code can be technically correct and stylistically consistent but still wrong from the business perspective.
The “code correctness” problem is not necessarily about the lack of an agent’s capability. It’s more of a structural issue. What requirements can an agent follow if there are none? Well, none.
Here’s what this looks like in practice:
- A dev uses Copilot or Claude to generate a function based on a Jira ticket.
- The AI review agent scans the PR and finds no vulnerabilities. The style is good, and coverage is present. 👍
- The PR merges, yet the function fails to handle a case that was in acceptance criteria but not in the code.
- No alerts, and the bug quietly makes it to production. 🚀
The automated steps are not to blame, though. Nothing failed in execution. They all did everything as designed.
What Automated AI Review Cannot Check Structurally
Let’s see what no automated review tool (regardless of how sophisticated the underlying model is) can reliably verify:
- Intent: A reviewing agent has no authoritative source of what code is supposed to do. It can infer intent from comments, function names, and the overall context, but inference does not equal verification.
- Business logic: A function can be technically correct and tested yet still wrong about what the business needs it to do.
- Spec compliance: If a spec has been written and approved by humans, code can be checked against it. However, if no such document exists (or if the same AI agent that has generated the code has also interpreted the requirements), there is no outside reference point.
The expensive bugs usually live in that small gap between “passed automated review” and “is this in spec”.
Human Judgment in the Loop
Humans still have the most leverage in the AI-boosted system; after all, those neurons count for something. So, a better way to frame it would be where they should go, not whether.
Now, it is true that a human review applied to every PR is costly. Plus, it’s not scalable alongside AI-assisted development. However, targeted human review is practical and valuable:
| Review Point | What Humans Verify | Why AI Can’t Own This |
|---|---|---|
| Spec review | Requirements are complete, unambiguous, and testable | AI can generate specs but cannot validate them against unstated business needs. |
| Acceptance criteria sign-off | Edge cases are covered, success conditions are explicit | Domain knowledge outside the codebase is required. |
| Architectural decisions | New patterns, service boundaries, data ownership | Long-term consequences aren’t encoded in any training set. |
| Post-implementation spec comparison | Does the code match what the spec said? | An independent reference, the spec itself, is necessary. |
| Incident post-mortems | What spec or review failure allowed this? | Causal reasoning about intent vs. outcome is needed. |
AI reviews are most valuable when applied to everything below that line: catching regressions, style enforcements, flagging bad patterns, and the volume reductions of low-signal issues that drain human brain’s bandwidth.
The Spec as the Anchor
Having a review spec that is human-improved is the anchor that we can verify against. AI can draft specs, as long as you make sure a human set of eyes goes over them, as well.
| Process | Without Spec | With Spec |
|---|---|---|
| Code generation | AI interprets requirements ad hoc. | AI works against reviewed acceptance criteria. |
| Automated review | Pattern-matches against known-good code. | Deviations from specified behavior can be flagged. |
| PR review | Reviewer guesses intent from the diff. | Reviewer compares implementation to the spec. |
| QA testing | Test cases derived from implementation. | Test cases derived from the spec, independent of implementation. |
| Incident response | “What was this supposed to do?” | Answer lives in the spec history. |
| Onboarding | Engineers read code to infer intent. | Engineers read specs first, then code. |
The spec is not a replacement for automated reviews, whether LLM- or scanner-based. Instead, it gives them something they lack: a sanity check. See more about Verification layers.
Next Steps
An automated review handles the volume (the syntax, style, coverage signals), while human judgment is in charge of spec approval before code is written. Aviator already covers both sides with its Runbooks for spec-driven workflows and FlexReview for reviewer assignment.
The missing piece is verifying whether the implementation actually matches the approved spec. That’s what we want to address with Aviator Verify. It’s not AI reading a diff and guessing intent. Aviator Verify parses the code and runs deterministic checks against each acceptance criterion. Same code, same result at each run.
We’re launching soon. Sign up for early access to get in before general availability.
FAQ
Is this just TDD?
TDD helps when tests come from the spec rather than AI. When AI generates both tests and code from the same ambiguous prompt, the suite can pass and still be wrong. Read more about spec-driven development if you are curious.
Does this mean every PR needs a human reviewer?
No. You move the human approval a step earlier: to verifying intent. If you need help properly routing the PRs to the right humans, though, Aviator’s Inbox can help.
What if the team is too fast for specs?
Then you’re generating code faster than anyone can realistically verify whether it’s correct. It’s also a sign that specs feel like a heavy document someone has to own. That’s not particularly true. The intent already exists inside a prompt or a ticket. You do not need to write new documents from scratch but capture what you were thinking in a reviewable form.
Can a better model close the gap?
Not without an external reference. Better inference is still inference. Intent lives in the requirements.
¯\(ツ)/¯
How is deterministic verification different from AI code review?
AI code review reads the diff and leaves comments that vary between runs. Deterministic verification checks code against declared criteria and produces the same result every time with a full audit trail.
Frequently Asked Questions
Is this just TDD?
TDD helps when tests come from the spec rather than AI. When AI generates both tests and code from the same ambiguous prompt, the suite can pass and still be wrong. Read more about spec-driven development if you are curious.
Does this mean every PR needs a human reviewer?
No. You move the human approval a step earlier: to verifying intent. If you need help properly routing the PRs to the right humans, though, Aviator’s Inbox can help.
What if the team is too fast for specs?
Then you're generating code faster than anyone can realistically verify whether it's correct. It’s also a sign that specs feel like a heavy document someone has to own. That’s not particularly true. The intent already exists inside a prompt or a ticket. You do not need to write new documents from scratch but capture what you were thinking in a reviewable form.
Can a better model close the gap?
Not without an external reference. Better inference is still inference. Intent lives in the requirements.
¯\(ツ)/¯
How is deterministic verification different from AI code review?
AI code review reads the diff and leaves comments that vary between runs. Deterministic verification checks code against declared criteria and produces the same result every time with a full audit trail.


