Understanding the mental model behind GCP IAM: from identities to hierarchy


Every cloud provider has an access management system. However, every system not only relies on different concepts but behaves differently from its competitors. If you are familiar with AWS, for example, you might feel GCP’s access management is awkward.
Similarly, when you first learn Git, you might have no idea what’s going on. However, once you understand Git’s object model like blob, tree, commit, refs, you feel more comfortable with Git operations.
This article provides the basic mental model that is behind Google Cloud Platform’s (GCP) Identity and Access Management (IAM).

The complexity of GCP IAM
The foundation of GCP IAM is simple tuple matching. We can express access config “User X is allowed to do Y on a resource Z” as a tuple of (X, Y, Z). Whenever a user tries to do a certain operation in GCP, the service checks if such a tuple (X, Y, Z) is configured by the user, and if so, allows the operation.
However, the actual surface of GCP IAM is way more complicated. Let’s take a look at a more concrete example. There is a GCE VM named jumpbox, and alice@yourcompany.com wants to stop this VM. GCP IAM Policy is configured like this:
- User
bob@yourcompany.comis anOwnerof the GCP VMjumpbox - Group
sre@yourcompany.comis aCompute Adminof the GCP Project
When alice@yourcompany.com tries to stop jumpbox VM, GCP IAM tries to find a tuple (alice@yourcompany.com, compute.instances.stop, jumpbox). Assuming that Alice is a member of SRE, this matches with the second GCP IAM Policy entry that is configured at the GCP Project.
Only a handful of people would understand this scenario at first sight. If you realize “Oh, that’s how Zanzibar is used” at this point, you can stop reading now.
Great, some of you are still here. This article is to help you understand the scenario described above.
The confusing part of this is that, even though the concept “User X is allowed to do Y on a resource Z” looks simple, the actual config and permission checks look like handling the variables X, Y, Z differently. You can observe the following:
- Apparently, GCP has a concept of Users and Groups, and you can give permissions to groups as well.
- There should be some relationships between
Owner,Compute Adminandcompute.instances.stop. Not sure where thiscompute.instances.stopcomes from, but it looks like it’s about permission to stop a GCP VM. - Instead of checking the permissions given on
jumpboxVM, the GCP IAM also checks the permission at the GCP Project. This seems that there’s an inheritance structure between objects.
We’ll look into these one by one.
GCP Identities
Basically, GCP has two kinds of identities:
- Human user accounts: Your Google account. You might have
bob@yourcompany.comGoogle Account, and this is a user identity at GCP. - Service accounts: You can create a machine user in GCP. These users do not have a password, and a credential is obtained in other ways. Each service account has an email address like
my-service@my-project.iam.gserviceaccount.com, while this cannot be used for receiving emails.
When you call GCP APIs, you need to attach a credential that attests to one of these account kinds. You would like to use human user accounts for development and use service accounts for production etc. If you run your application in GCP, you should be able to specify which service account the application should use. The GCP client library automatically detects this config, and it uses a credential of that service account.
Groups of GCP Identities
There are groups of GCP identities. Consider these as Set<GCPIdentity> that can be used for referencing a set of accounts when giving permissions.
- Google Groups: While Google Groups is primarily known as a mailing list service, this is used as a group of GCP identities in GCP. This is useful for organizing human teams. For example, you can make
frontend-eng@yourcompany.com,backend-eng@yourcompany.com, andsre@yourcompany.comand give these groups the permissions necessary for their job. When a new person joins a team, they can join one of those team Google Groups and they automatically get permissions necessary for their job, without changing the GCP configuration. - Google Workspace account: If you use
[yourcompany.com]as a domain for Google Workspace,yourcompany.comitself can be treated as a group of GCP identities. This group contains all of@yourcompany.comusers. This is useful if you want to give read-only permission for all employees on a dashboard, for example.
Unlike human user accounts and service accounts, these groups are not something you can log in or create a credential; you cannot call GCP API as frontend-eng@yourcompany.com. These are used for access control.
Roles and permissions
Most of the operations on GCP are done through GCP APIs. Whether you use GCP Console or gcloud CLI, they are ultimately making a GCP API call. You can see the actual HTTP request gcloud is making by using gcloud --log-http for example.
GCP APIs are designed based on API Improvement Proposals, and as described in HTTP and gRPC Transcoding, APIs are defined by gRPC and exposed as REST APIs. Each gRPC method has one associated permission. When you make a REST API call, it’s converted to a gRPC call, and permission is checked.
In the GCP API reference, there’s a section that describes which permission you need to call the method.
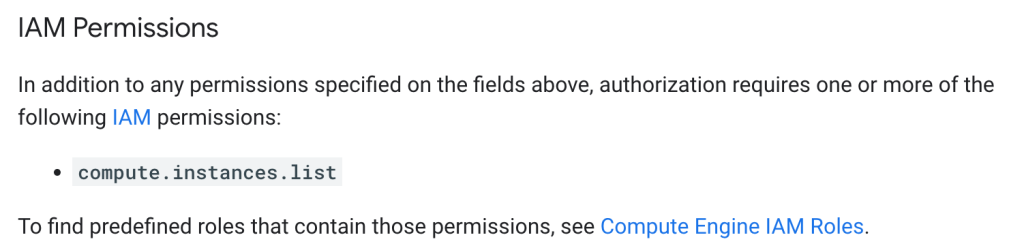
Getting a list of VMs requires compute.instances.list permission. https://cloud.google.com/compute/docs/reference/rest/v1/instances/list#iam-permissions
Roles are named sets of permissions. When you grant permissions to users and service accounts, you give them via roles, not directly by naming which permission they should have. You can define your own customized role, and technically if you create a role that contains single permission, you can effectively give permission one by one.
However, GCP provides pre-defined roles that fit typical use cases, and you should be able to find one that fits your usage in most cases.
Resource hierarchy
GCP resources such as virtual machines and load balancers have a hierarchy. As mentioned above, GCP APIs are designed based on API Improvement Proposals, and AIP-122 defines the hierarchical nature of the resources.
All resources are contained in a GCP Project, and a GCP Project may belong to a folder and/or organization. You can set an access control policy (IAM Policy) on each hierarchy. Every GCP resource type should have SetIamPolicy and GetIamPolicy methods so that a policy can be attached to a specific resource.
Because there is a hierarchy of resources, there is a parent-child relationship between them. The parent policy is applied to its children. For example, if you give a person permission to read cloud storage files at a GCP Project level, that person can read all the files under that project.
Revisiting the original example
At the beginning of the article, we looked at an example IAM Policy like this:
- User
bob@yourcompany.comis anOwnerof the GCP VMjumpbox - Group
sre@yourcompany.comis aCompute Adminof the GCP Project
In IAM Policy, this is expressed below:
# In IAM Policy of the jumpbox VM
bindings:
- members:
- user:bob@yourcompany.com
role: roles/owner
# In IAM Policy of the GCP Project
bindings:
- members:
- group:sre@yourcompany.com
role: roles/compute.adminEvery GCP resource can have an IAM Policy. In this case, the VM instance has a policy, and the GCP project has another policy. Because the resources are hierarchical, the GCP project policy is also applied in addition to the VM-level policy for the access check to the jumpbox VM.
When alice@yourcompany.com is trying to delete the jumpbox VM, whether gcloud CLI or GCP Console does it, they invoke compute engine API’s instances.delete under the hood.
According to the API reference, this requires compute.instances.delete IAM permission. The IAM permission check of (alice@yourcompany.com, compute.instances.delete, jumpbox) goes through the expansion of Google Groups, IAM roles, and resource hierarchy, and it should permit them to delete the VM.
Technical aspects of GCP IAM
Throughout the article, we have a position that the access checking is a tuple matching. In this last section, we provide a pointer to the technical aspect of GCP IAM around this.
GCP IAM is built on top of a system called Zanzibar. This system is basically a distributed tuple matching system designed for ACL. It uses (object, relation, user) tuples as its foundation, and it allows configuration on how the tuples can be expanded. You should be able to see how Zanzibar and GCP IAM are connected with this.
There are some open-source Zanzibar implementations. Understanding the object models of GCP IAM would help if you need to implement your own access control mechanism based on those implementations.
Aviator: Automate your cumbersome merge processes
Aviator automates tedious developer workflows by managing git Pull Requests (PRs) and continuous integration test (CI) runs to help your team avoid broken builds, streamline cumbersome merge processes, manage cross-PR dependencies, and handle flaky tests while maintaining their security compliance.
There are 4 key components to Aviator:
- MergeQueue – an automated queue that manages the merging workflow for your GitHub repository to help protect important branches from broken builds. The Aviator bot uses GitHub Labels to identify Pull Requests (PRs) that are ready to be merged, validates CI checks, processes semantic conflicts, and merges the PRs automatically.
- ChangeSets – workflows to synchronize validating and merging multiple PRs within the same repository or multiple repositories. Useful when your team often sees groups of related PRs that need to be merged together, or otherwise treated as a single broader unit of change.
- TestDeck – a tool to automatically detect, take action on, and process results from flaky tests in your CI infrastructure.
- Stacked PRs CLI – a command line tool that helps developers manage cross-PR dependencies. This tool also automates syncing and merging of stacked PRs. Useful when your team wants to promote a culture of smaller, incremental PRs instead of large changes, or when your workflows involve keeping multiple, dependent PRs in sync.


