
Rethinking code reviews with stacked PRs
This post explores shift-left principles and suggests that stacked PRs will become increasingly useful.

The peer code review process is an essential part of software development. It helps maintain software quality and promotes adherence to standards, project requirements, style guides, and facilitates learning and knowledge transfer.
Code review effectiveness
While the effectiveness is high for reviewing sufficiently small code changes, it drops exponentially with the increase in the size of the change. To sustain the necessary level of mental focus to be effective, large code reviews are exhausting. Usually, the longer the review duration gets, the less effective the overall review becomes:
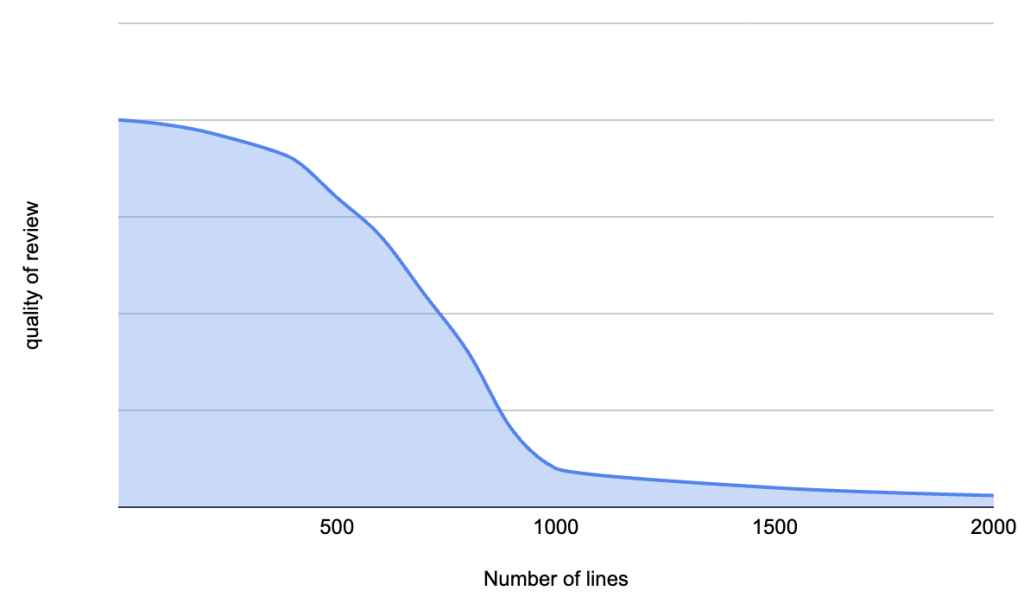
So why can’t we just restrict the size of the pull requests (PRs)? While many changes can start small, suddenly a small two-line change can grow into a 500-line refactor including multiple back-and-forth conversations with reviewers. Some engineering teams also maintain long-running feature branches as they continue working, making it hard to review.
So, how do we strike the right balance? Simple. Use stacked PRs.

What are stacked PRs?
Stacked pull requests make smaller, iterative changes and are stacked on top of each other instead of bundling large monolith changes in a single pull request. Each PR in the stack focuses on one logical change only, making the review process more manageable and less time-consuming.
We also wrote a post last year explaining how this help represents code changes as a narrative instead of breaking things down by files or features.
Why stacked PRs?
Other than building a culture of more effective code reviews, there are a few other benefits of stacked PRs:
Early code review feedback
Imagine that you are implementing a large feature. Instead of creating the entire feature and then requesting a code review, consider carving out the initial framework and promptly putting it up for feedback. This could potentially save you countless hours by getting early feedback on your design.
Faster CI feedback cycle
Stacked PRs support the shift-left practice because changes are continuously integrated and tested, which allows for early detection and rectification of issues. The changes are merged in bits and pieces catching any issues early vs merging one giant change hoping it does not bring down prod!
Knowledge sharing
Code reviews are also wonderful for posterity. Your code changes are narrating your thought process behind implementing a feature, therefore, the breakdown of changes creates more effective knowledge transfer. It’s easier for team members to understand the changes, which promotes better knowledge sharing for the future.
Staying unblocked
Waiting on getting code reviewed and approved can be a frustrating process. With stacked PRs, the developers can work on multiple parts of a feature without waiting for reviewers to approve previous PRs
What’s the catch?
So, why don’t more developers use stacked PRs for code reviews?
Although this stacked PR workflow addresses both the desired practices of keeping code reviews manageable and developers productive, unfortunately, it is not supported very well natively by either git or GitHub. As a result, several tools have been developed across the open-source community to enable engineers to incorporate this stacking technique into the existing git and GitHub platforms. But stacking the PRs is only part of the story.
Updating
As we get code review feedback and we make changes to part of the stack, we have to now rebase and resolve conflicts at all subsequent branches.
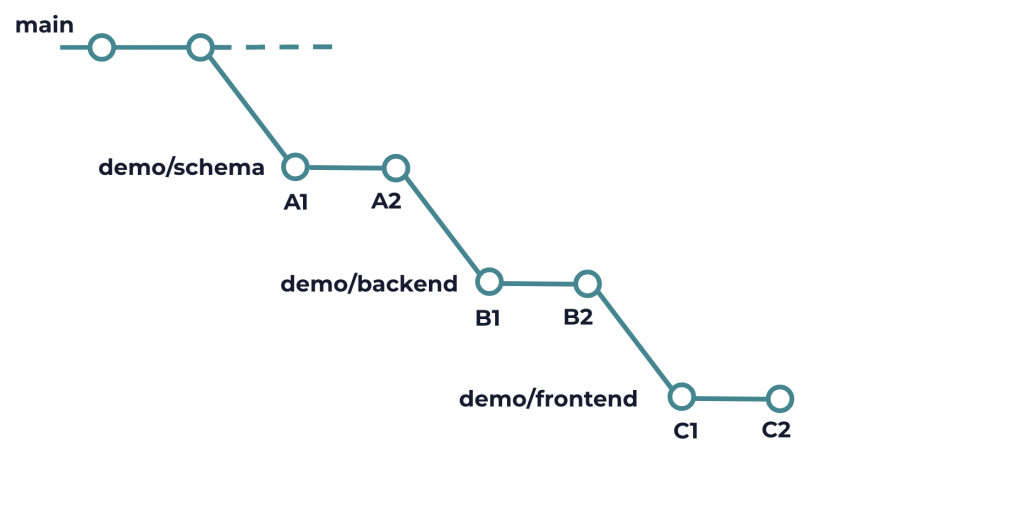
Let’s take an example. Imagine that you are working on a change that requires making a schema change, a backend change, and a frontend change. With that, you can now send a simple schema change for review first, and while that’s being reviewed you can start working on the backend and frontend. Using stacked PRs, all these 3 changes can be reviewed by 3 different reviews.
In this case, you may have a stack that looks like this where demo/schema, demo/backend and demo/frontend represents the 3 branches stacked on top of each other.
So far this makes sense, but what if you got some code review comments on the schema change that requires creating a new commit? Suddenly your commit history looks like this:
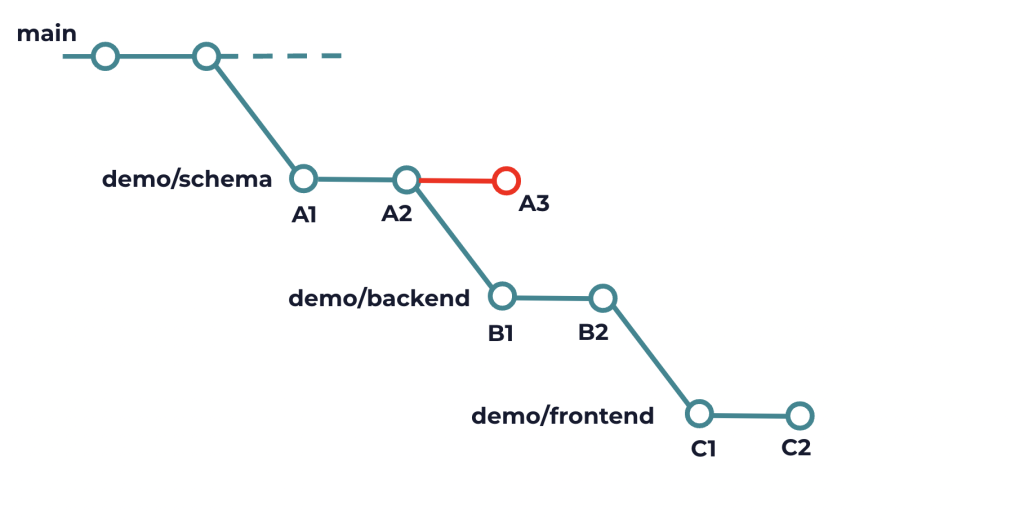
Now you have to manually rebase all subsequent branches and resolve conflicts at every stage. Imagine if you have 10 stacked branches where you may have to resolve the conflicts 10 times.
Merging
But that’s not all, merging a PR in the stack can be a real nightmare. You have 3 options squash, merge and rebase to merge a PR. Let’s try to understand what goes behind the scenes in each one.
- In the case of a
squashcommit, Git takes changes from all the existing commits of the PR and rewrites them into a single commit. In this case, no history is maintained on where those changes came from - A
mergecommit is a special type of Git commit that is represented by a combination of two or more commits. So, it works very similar to asquashcommit but it also captures information about its parents. In a typical scenario, a merge commit has two parents: the last commit on the base branch (where the PR is merged) and the top commit on the feature branch that was merged. Although this approach gives more context to the commit history, it inadvertently creates non-linear git-history that can be undesirable. - Finally, in case of a
rebaseand merge, Git will rewrite the commits onto the base branch. So similar tosquashcommit option, it will lose any history associated with the original commits.
Typically if you are using the merge commit strategy while stacking PRs, your life will be a bit simpler, but most teams discourage using that strategy to keep the git-history clean. That means you are likely using either a squash or a rebase merge. And that creates a merge conflict for all subsequent unmerged stacked branches.
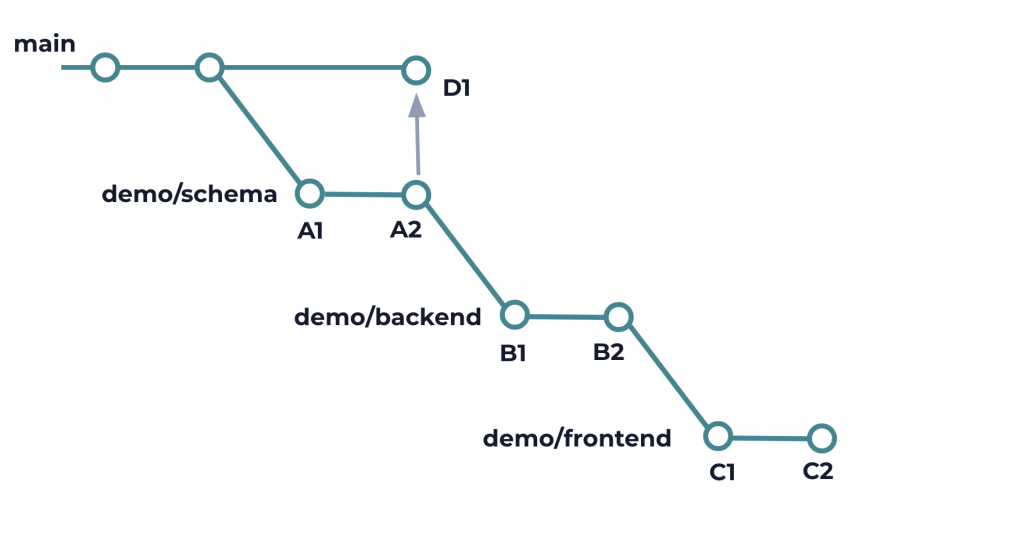
In the example above, let’s say we squash merge the first branch demo/schema into mainline. It will create a new commit D1 that contains changes of A1 and A2. Since Git does not know where D1 came from, and demo/backend is still based on A2, trying to rebase demo/backend on top of the mainline will create merge conflicts.
Likewise, rebasing demo/frontend after rebasing demo/backend will also cause the same issues. So if you had ten stacked branches and you squash merged one of them, you would have to resolve these conflicts nine times.
We are still just scratching the surface, there are many other use cases such as reordering commits, splitting, folding, and renaming branches, that can create huge overhead to manage when dealing with stacked PRs.
That’s why we built stacked PRs management as part of Aviator.
Why Aviator CLI is different
Think of Aviator as an augmentation layer that sits on top of your existing tooling. Aviator connects with GitHub, Slack, Chrome, and Git CLI to provide an enhanced developer experience.
Aviator CLI works seamlessly with everything else! The CLI isn’t just a layer on top of Git, but also understands the context of stacks across GitHub. Let’s consider an example.
Creating a stack
Creating a stack is fairly straightforward. Except in this case, we use av CLI to create the branches to ensure that the stack is tracked. For instance, to create your schema branch and corresponding PR, follow the steps below.
av stack branch demo/schema
# make schema changes
git commit -a -m "[demo] schema changes"
av pr createSince Aviator is also connected to your GitHub, it makes it easy for you to visualize the stack.
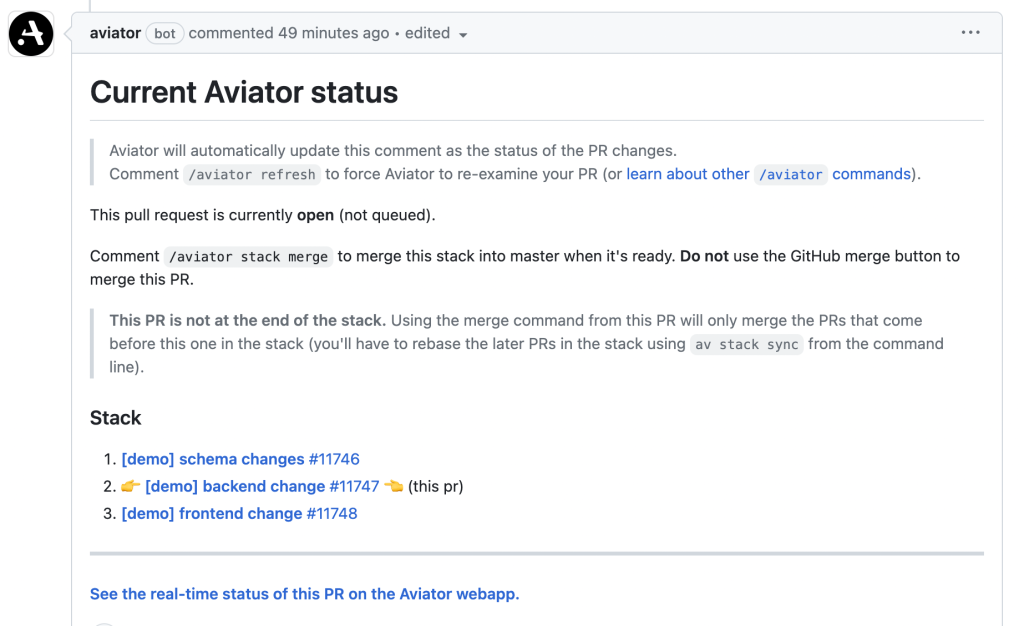
Or if you want to visualize it from the terminal, you can still do that with the CLI commands:

Updating the stack
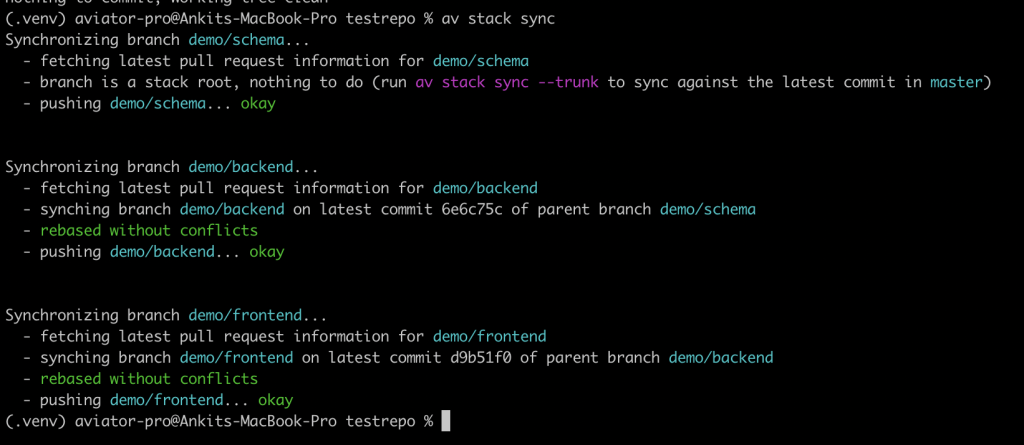
Using the stack now becomes a cakewalk. You can add new commits to any branch, and simply run av stack sync from anywhere in the stack to synchronize all branches. Aviator automatically rebases all the branches for you, and if there’s a real merge conflict, you just have to resolve it once.
Merging the stack
This is where Aviator tools easily stand out from any existing tooling. At Aviator, we have built one of the most advanced MergeQueue to manage auto-merging thousands of changes at scale. Aviator supports seamless integration with the CLI and stacked PRs. So to merge partial or full stack of PRs, you can assign them to Aviator MergeQueue using CLI av pr queue or by posting a comment in GitHub: /aviator stack merge.
Aviator automatically handles validating, updating, and auto-merging all queued stacks in order.
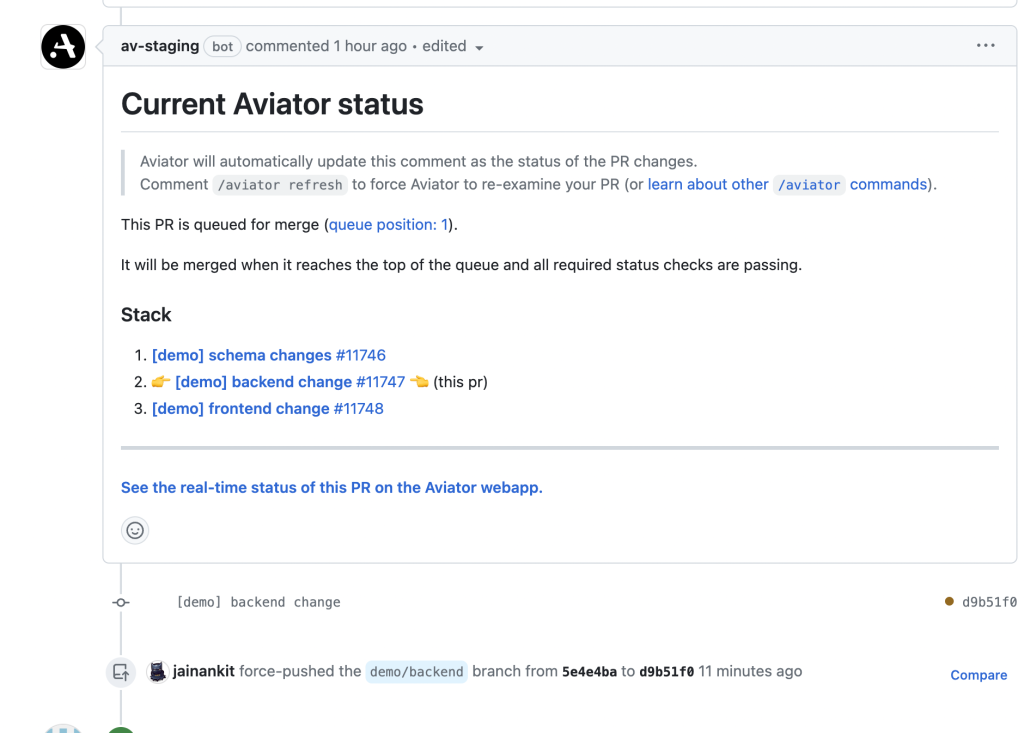
Now when the PRs are merged, you can this time run av stack sync --trunk to update all PRs and clean out all merged PRs.
Shift-Left is the future
Stacked PRs might initially seem like more work due to the need to break down changes into smaller parts. However, the increase in code review efficiency, faster feedback loops, and enhanced learning opportunities will surely outweigh this overhead. As we continue embracing the shift-left principles, stacked PRs will become increasingly useful.
The Aviator CLI provides a great way to manage stacked PRs with a lot less tedium. The CLI is open-source and completely free. We would love for you to try it out and share your feedback on our discussion board.
At Aviator, we are building developer productivity tools from first principles to empower developers to build faster and better.









