
How High-Throughput Teams Merge Faster Using Parallel CI and Batch CI Runs
High-throughput engineering teams often hit merge delays because CI pipelines run in strict sequence. Parallel CI fixes this by running jobs concurrently, cutting down wall-clock time and giving faster feedback. Batch CI takes it further by grouping multiple pull requests into a single run, reducing redundant builds and surfacing conflicts earlier. Together, they transform CI from a bottleneck into a throughput engine, helping teams merge faster, with fewer conflicts and a smoother developer experience.

TL;DR
- High-throughput teams struggle with merge delays due to serialized CI pipelines.
- Parallel CI reduces queue wait time by running jobs concurrently, not one-by-one.
- Batch CI groups similar changes together to minimize redundant builds and improve efficiency.
- Combined, these approaches unlock faster feedback loops, fewer conflicts, and a smoother developer experience.
- Tools like Buildkite, CircleCI, and GitHub Actions support parallelism and batching for teams scaling CI.
Introduction
In high-velocity engineering orgs, the codebase isn’t just a shared resource, it’s a battleground of merge races, rebases, and queue backlogs. The problem becomes particularly visible in companies where multiple developers are pushing changes several times an hour. What used to be a simple “push-and-merge” becomes a nerve-wracking wait for CI to catch up. Seconds turn to minutes, minutes into hours. And all the while, your carefully reviewed code sits idle behind someone else’s test suite.
According to a 2023 LinearB report on developer velocity, engineering teams lose an average of 31.6% of their active coding hours each week waiting on CI, builds, and deploy queues (source). That’s nearly 1.5 days per week wasted.
As one developer on r/github put it:

This post breaks down how teams at scale can cut through that bottleneck using Parallel CI and Batch CI runs. These are not vague process suggestions, they’re architectural shifts in how CI pipelines are built and triggered. We’ll show why sequential pipelines are a drag on throughput, and how smarter concurrency transforms CI from a blocker to a multiplier.
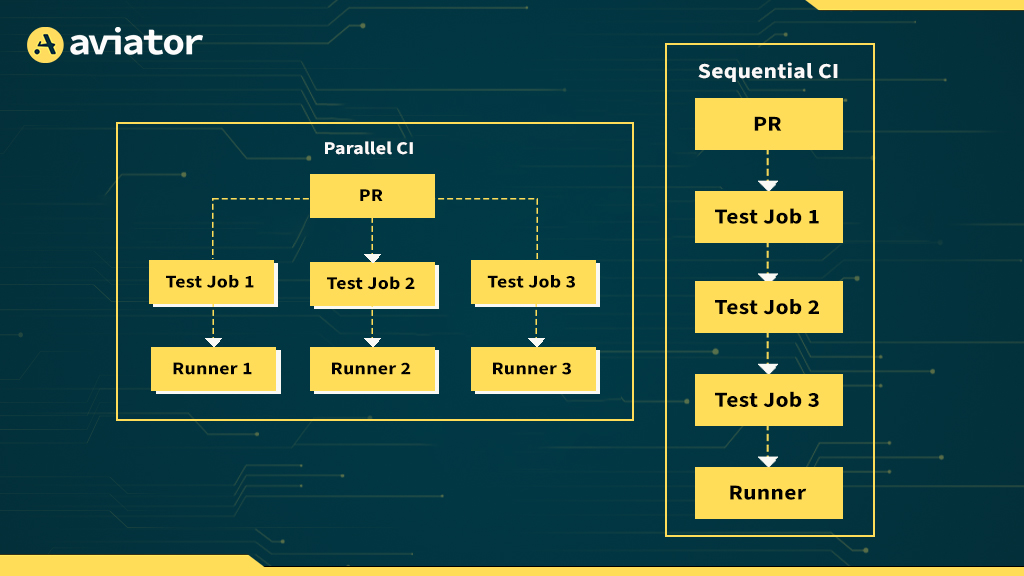
The CI Bottleneck in High-Throughput Teams
Imagine a toll booth with only one lane, and you’ve got 50 cars arriving at once. That’s your typical CI pipeline in a busy engineering team: serialized, overloaded, and backed up fast. As more developers push simultaneously, especially around release windows or sprint cutoffs, the pipeline becomes the bottleneck, not the code quality.
When CI runs in a strictly serialized fashion, every push waits for the previous job to finish. This naturally leads to queue congestion, where even small commits sit in limbo behind longer test runs. Engineers who just want to validate a one-line config change are stuck waiting behind full-stack E2E test suites from a different team.
Merge velocity takes a direct hit. Developers either wait altogether (“CI is jammed again”) or start gaming the system, merging without full tests, batching unrelated commits, or running tests locally and skipping CI altogether. These workarounds introduce risk and fragility into production pipelines.
Merge conflicts become more common, too. If multiple branches are queued behind slow CI runs, the trunk gets updated several times in the interim. Rebase pain increases, especially in monorepos where a single shared pipeline governs dozens of services. By the time your CI finally finishes, your code may already be stale.
And perhaps most toxic of all: developer morale suffers. Nobody wants to feel like their tools are fighting them. Waiting on CI drains focus, encourages context switching, and leads to longer PR cycles. What should’ve been a smooth code-review-and-merge becomes a half-day ordeal.
How Parallel CI Eliminates Sequential Bottlenecks
Parallel CI is like opening up multiple lanes at the toll booth. Rather than one massive test suite blocking everything behind it, jobs are distributed across multiple workers or containers that run concurrently. This doesn’t just reduce wait times, it also improves the structure and observability of your pipeline.
Let’s say your CI pipeline has five major stages: linting, unit tests, integration tests, E2E, and deployment validation. In a sequential pipeline, all these stages block on each other. In a parallel setup, you might run all test stages simultaneously, with results aggregated at the end. The difference isn’t just a few seconds, it can be minutes shaved off every build, multiplied across dozens of developers.
Parallelism can be achieved on several layers:
- Job-level parallelism, where different jobs run on separate agents.
- Matrix builds, which run the same job across different environments (e.g., Node.js 16 vs. 18).
- Test sharding, where large test suites are broken into chunks and distributed to parallel runners.
With tools like GitHub Actions, CircleCI, and Buildkite, this is increasingly easy to configure. YAML pipelines now let you define jobs with needs: and strategy: options to control parallel execution. Some tools even auto-scale runners based on current workload, meaning your CI can elastically match the pace of your team.
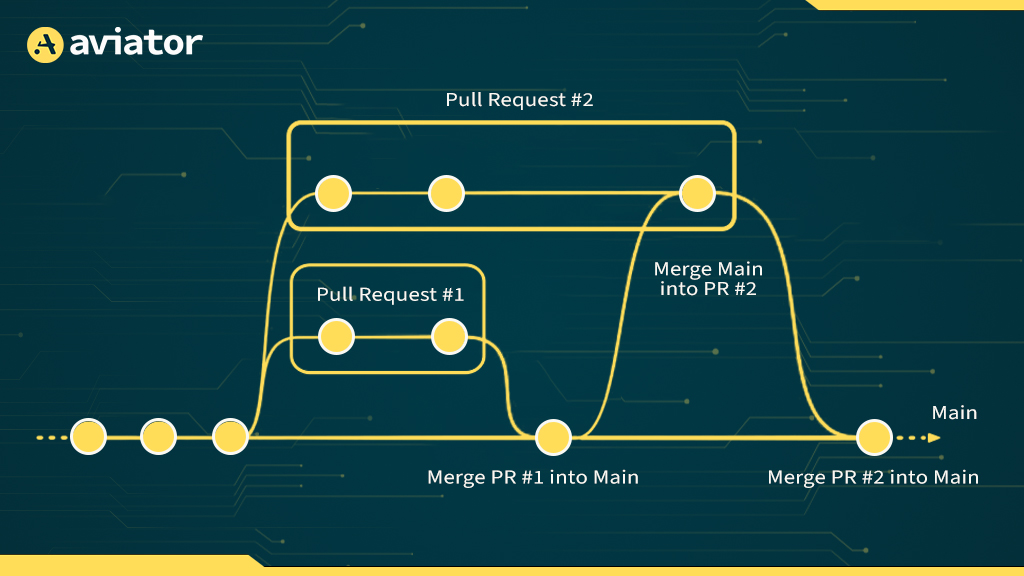
But it’s not just about speed. Parallel CI also increases fault isolation. If one job fails, others may still pass, giving you partial visibility into what’s broken. It makes debugging faster, and developers don’t have to restart entire pipelines just to fix a flaky test.
So, this brings us to the point that what actually is Parallel CI?
What Is Parallel CI?
Parallel CI refers to the practice of executing multiple Continuous Integration (CI) jobs at the same time, rather than one after another. Instead of treating your test suite like a long single-file checklist, you break it into smaller, independent jobs, like splitting a grocery list among friends. Each one picks up a piece, finishes faster, and comes back to the checkout lane together.
This concept becomes especially useful when your test suite is large and slow. For example, imagine your repo contains thousands of unit and integration tests. Rather than running them in a massive monolithic job, you shard them, maybe by feature, directory, or tagging logic, and distribute each shard to a separate runner. All these shards then run in parallel, returning results simultaneously and dramatically cutting the total wall-clock time.
Aviator’s MergeQueue supports this model through its Parallel Mode, allowing CI pipelines to run multiple builds concurrently across a pool of runners. This approach aligns with modern developer expectations, especially in teams pushing dozens of PRs per day, because it accelerates feedback loops without requiring PR authors to change their workflow.
One of the biggest wins here is reduced wait time. When you parallelize your jobs, CI becomes a throughput amplifier. You don’t need to buy more time; you buy more lanes on the freeway. Each commit gets processed as soon as it’s ready, not when the last guy’s job finally finishes.
Another major advantage is horizontal scalability. With cloud-native infrastructure (like Kubernetes or AWS Fargate), you can auto-scale your runners and dispatch test workloads to multiple pods or containers. Self-hosted CI setups like Jenkins or Drone also support this with worker nodes. Teams with elastic infra can spin up tens, or hundreds, of workers on demand to keep build latency near zero, even under heavy commit volume.
That said, there are trade-offs. You need a pipeline structure that supports smart test splitting. Arbitrary division won’t help if some shards take 10x longer than others. Many teams integrate historical timing data or code coverage signals to ensure even distribution. You also need your test runners and CI system to support isolation, parallel jobs must be sandboxed, not stepping on shared resources like databases or file systems.
In essence, Parallel CI is about recognizing that CI time is developer time, and it’s too expensive to waste in a single-threaded queue. So, let’s see another strategy i.e., Batch CI?
What Is Batch CI?
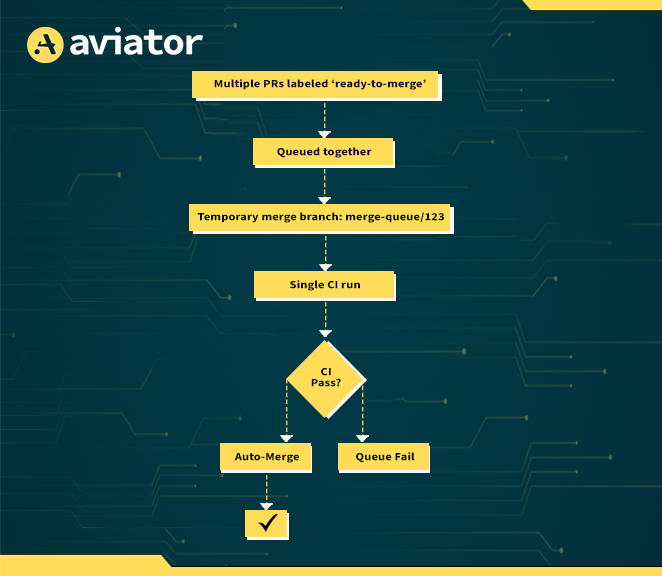
Batch CI is the strategy of bundling multiple commits or pull requests together into a single CI run, treating them as a cohesive group instead of testing each change independently. Think of it as loading passengers into a shared bus rather than having each one drive a car to the same destination. Everyone gets there together, faster and with less traffic.
This approach is commonly implemented using merge queues, which temporarily stage multiple PRs into a single synthetic branch. The CI system then runs once against that aggregate state. If the combined changes pass tests, each PR is eligible for merge. If not, the queue can be bisected and tested again, helping identify which PR broke the build.
Aviator supports this through its Batching concept, where multiple PRs are grouped, validated, and merged in a clean, deterministic sequence. This is especially useful for teams where CI minutes are expensive or queue delays are common.
The biggest benefit of batch CI is reduction in total CI workload. If 10 devs submit 10 trivial PRs, running CI 10 times wastes compute, clutters logs, and delays merges. Batch CI runs once, saving resources while still offering confidence in merge safety.
Batching also helps surface integration issues earlier. Since the group of PRs is tested together, any hidden conflicts between two changes are caught before merge, not after they’ve landed on main. This is particularly useful in monorepos or tightly-coupled services, where seemingly unrelated changes may collide.
From a developer’s perspective, batch CI improves merge safety and predictability. You don’t merge into a moving target; you merge into a validated state. You don’t get “surprise red” on main an hour later. Instead, there’s a deterministic flow: your PR waits in the queue, gets grouped, validated, and merges only if the system says it’s clean.
Of course, it’s not magic. Batch CI requires infrastructure that supports temporary merge branches, often with names like merge-queue/123. These must be ephemeral, conflict-aware, and visible to both CI and GitHub/GitLab bots. If a conflict is detected, the PR must be re-queued or flagged for manual resolution. Tools like Aviator MergeQueue or GitHub’s own gh-merge-bot automate this workflow by managing queue state, merging logic, and PR labeling.
There’s also the risk that a failing batch will delay many otherwise-valid PRs. That’s why robust batching systems include automatic bisection, splitting failing batches into smaller groups to isolate bad commits.
Batch CI isn’t just a performance hack, it’s a CI philosophy. It assumes the pipeline is a system, not a series of independent events. It optimizes for system-level success rather than per-PR purity.
Combining Parallel CI and Batch CI for Maximum Efficiency
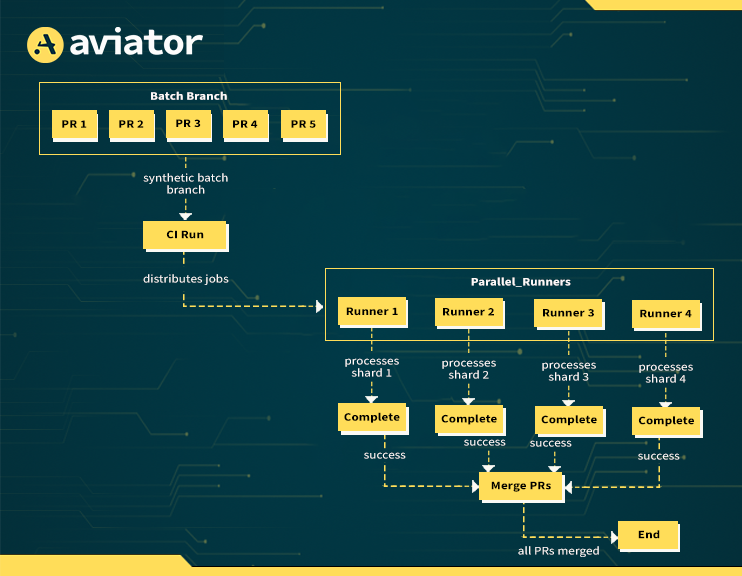
When used independently, both parallel and batch CI strategies offer substantial gains. But together? They create a force multiplier, drastically reducing time-to-merge while improving the reliability of your builds.
Here’s how the relationship works: Parallel CI reduces the time it takes to run each pipeline by executing jobs concurrently. Batch CI reduces the number of pipeline executions altogether by validating multiple pull requests at once. One works on the x-axis (time per job), the other on the y-axis (number of jobs). Combine them, and you’re not just shaving seconds, you’re unlocking order-of-magnitude improvements in CI efficiency.
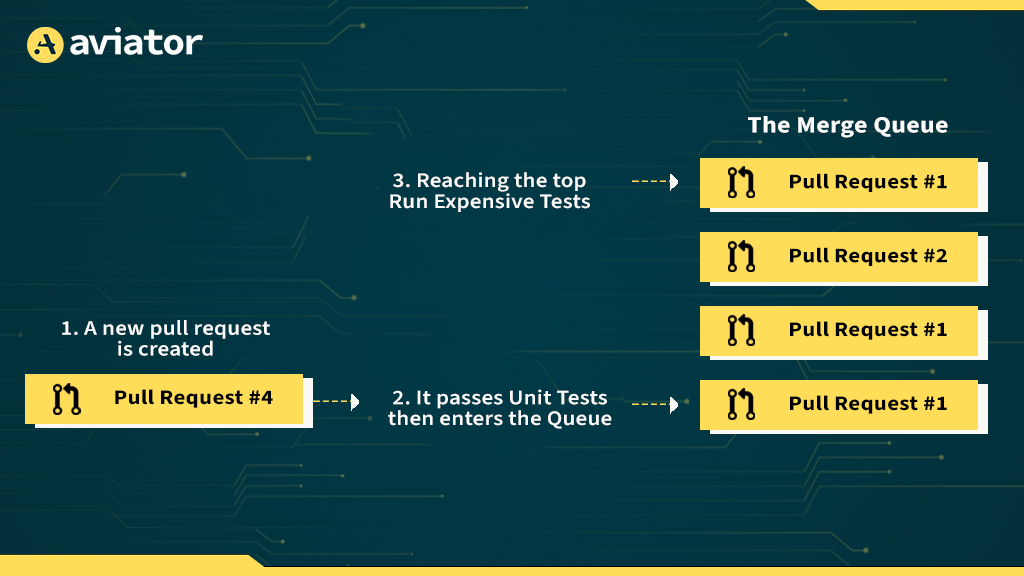
Think of this as a warehouse workflow. Parallel CI is like hiring more workers to process packages at the same time. Batch CI is like combining those packages into larger pallets so fewer deliveries are needed. The net effect is a system that’s both faster and leaner.
Let’s take a practical case: a high-throughput monorepo with 10 incoming PRs per hour, each requiring a full test matrix across 3 environments. Without optimization, that’s 30 CI runs, 10 PRs × 3 environments, executing back-to-back. With batching, you group those 10 PRs into 1 CI run, and with parallelization, those 3 environments are tested simultaneously. You’ve gone from 30 serialized runs to a single parallelized build. That’s a 30x runtime reduction without compromising confidence in the result.
This isn’t theory, it’s how companies like Shopify, Stripe, and Pinterest manage their CI pipelines today. Many use merge queues with auto-batching plus test shard parallelism at the infrastructure level. They’ve invested in deterministic pipelines that scale horizontally and avoid the noise and cost of duplicated CI runs.
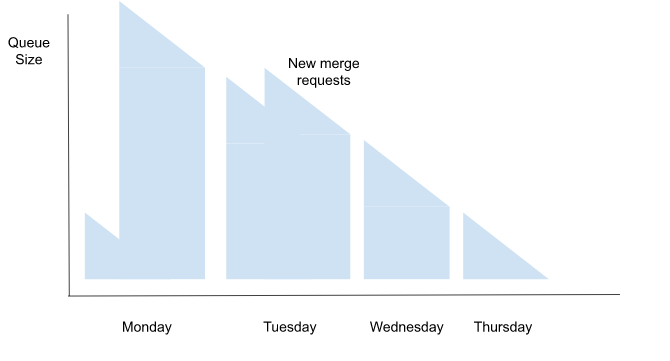
Merge throughput grows with batch size and success rate, while being inversely proportional to CI run duration.
What makes this combo even more powerful is that it scales with team size. As more developers push code, the batching logic absorbs the increase without flooding the CI system. And with proper test splitting and resource provisioning, the parallel runners can handle the extra workload without adding latency.
The only real challenge is coordination, ensuring the batch logic and parallel execution model can talk to each other, especially around job dependencies and caching. But tools like Aviator MergeQueue and GitHub’s Actions matrix strategy are built to handle this at scale.
If Parallel CI is the engine, Batch CI is the transmission. When synced correctly, you get optimal speed and control, enabling faster feedback, more merges per day, and happier developers.
Hands-on: Creating a GitHub CI Pipeline with Parallel + Batch Execution
You don’t need a massive infra team or enterprise CI contract to get started with this architecture. You can simulate both batch and parallel CI today using public tools like GitHub Actions and Aviator MergeQueue.
Let’s start with Batch CI. Services like MergeQueue let you plug into GitHub and immediately start queueing and batching PRs. You configure it to stage pull requests in a temporary merge-queue/ branch, which CI will validate before allowing them to merge into main. It even bisects failing batches and reruns tests as needed.
To try it:
- Connect your GitHub repo to MergeQueue.
- Set rules: batch size, timeouts, auto-retry behavior.
- Add a simple label like ready-to-merge, which triggers inclusion in the queue.
- Your PRs will now be merged only if the batched state passes CI.
Now for Parallel CI. In GitHub Actions, you can define a matrix strategy inside your workflow file to run jobs across different parameters, Node versions, OSes, or test shards. Here’s an example:
jobs:
test:
runs-on: ubuntu-latest
strategy:
matrix:
shard: [1, 2, 3, 4] # 4-way test parallelism
steps:
- uses: actions/checkout@v3
- name: Run tests
run: |
npm install
npm run test -- --shard=${{ matrix.shard }}In this setup, your test suite is logically split into four shards, each executed in parallel. You can use a test runner like Jest with –shard flags, or tools like knapsack-pro or pytest-xdist to auto-distribute tests based on size or duration.
To bring it all together:
- Configure your merge queue to batch PRs into a synthetic merge-queue branch.
- Point your GitHub Actions workflow to trigger on pushes to merge-queue.
- Inside that workflow, use matrix builds to parallelize test execution.
- Add fail-fast logic to abort slow or failing jobs early, freeing runners for the next batch.
You now have a CI system that:
- Merges only if a batched state passes CI
- Executes that CI run with concurrent job runners
- Optimizes both merge safety and execution speed
Even better, this setup scales. As your team grows and PR volume increases, you don’t need to change your workflow, just increase the number of shards or queue rules. The architecture remains resilient under pressure.
Flakiness Slows Down the Train: CI Throughput in the Real World
In theory, adding parallel CI and batching should speed things up. In practice, the first thing that breaks is trust. Your pipeline becomes fast, but unpredictable. Tests pass locally, fail in CI. A PR looks green on its own, but red when batched. Merge queues stall, developers hit retry, and everyone starts looking for workarounds. The bottleneck shifts, from compute to confidence.
What slows you down isn’t job duration, it’s test flakiness, noisy retries, and stale metrics. These are the silent killers of CI velocity. A single flaky integration test, triggered only 5% of the time, can paralyze a batch of 10 PRs. Multiply that across dozens of runs per day, and your “smart” pipeline becomes a minefield.
As one developer put it on Reddit:
“You can divide your CI usage by 5 by running E2E only when a PR is ready to merge… but flakiness kills it.”

So what does a healthy, real-world setup look like?
You need:
- A merge queue that supports batching, not just FIFO merge logic.
- Parallel shards across test dimensions (language versions, platforms, services).
- Visibility into which PRs failed in batch vs solo.
- Flake detection and retry strategy, quarantine buckets, soft fails, and auto-bisecting logic.
That’s what tools like Aviator MergeQueue or GitLab Merge Trains bake in.
And more importantly: you need to track throughput as a product metric, not just CI speed. Outschool put it best with their formula:
Throughput = Batch Size × Success Rate ÷ Duration
(source)
If you batch 5 PRs and flake on 1, your success rate is 0%. You’ve just wasted time and compute, and now 5 developers are waiting on reruns. It’s a system-level failure, not a bad test.
That’s why high-throughput teams obsess over queue times, batch pass rates, and retry volume, not just total CI runtime. They measure how often CI blocks deploys, not just how long it takes. Every CI decision is about protecting velocity, not checking a box.
If you want more deploys per day, you don’t just buy faster runners. You buy certainty, with clean test boundaries, confident merge gates, and telemetry that shows where the slowdown actually lives.
Conclusion
The CI pipeline used to be a tool to check the box, “does it build, does it test, good enough.” But in modern engineering organizations, it’s much more than that. It’s the primary throttle on merge velocity, developer focus, and ultimately, how fast your team ships.
Parallel CI unlocks horizontal scalability. It slices up slow, monolithic jobs and runs them concurrently across distributed computers. Batch CI reduces the frequency of builds by validating shared change sets. Together, they form a compound system that’s fast, reliable, and designed for teams that ship code all day, every day.
What starts as a performance optimization becomes a workflow shift. Developers no longer have to wait hours for CI. PRs no longer fight each other for merge slots. Your team goes from blocked to continuous.
Whether you’re running GitHub Actions or a full custom CI/CD stack, implementing these patterns is within reach. Start small: split tests into a matrix, configure a merge queue, measure the results. Over time, you’ll build a CI system that scales with your ambition.
FAQs
1. What is Parallel Execution in Automation?
Parallel execution refers to running multiple test jobs or pipeline steps at the same time rather than in sequence. This is often achieved through matrix builds or job-level concurrency in CI systems. It helps reduce the total duration of a build by utilizing more compute power simultaneously.
2. What is the Difference Between Serial and Parallel Execution?
In serial execution, each CI job runs one after another, waiting for the previous one to finish. In parallel execution, multiple jobs run concurrently, reducing the total time required to complete all tasks. Serial is simpler but slower; parallel is faster but needs orchestration and more resources.
3. What Do You Mean by Batching of CI?
Batching refers to combining multiple commits or pull requests into a single CI run. Instead of running CI for each PR individually, batching tests the group together to reduce load, surface integration issues early, and speed up merges. It’s especially useful in high-volume teams or monorepo environments.
4. What is Pipeline Caching?
Pipeline caching stores the output of expensive CI steps (like dependency installs or build artifacts) so that future jobs can reuse them instead of re-running the entire step. It reduces redundancy and speeds up pipeline runs. Common tools include GitHub Actions’ actions/cache and Bazel’s remote cache system.








