
Pre and post-merge tests using a merge queue

One of the key ingredients making developers productive is faster feedback loops. A fast feedback loop allows developers to identify and address issues promptly, leading to higher-quality code and faster release cycles.
Pre-merge and Post-merge tests
To maintain the good health of your system, there are a few types of tests that may be required. Validating these tests can take anywhere from a sub-second to several hours.
In the traditional waterfall model, testing is often a phase that occurs after development. However, the emphasis is on catching issues early in agile development and CI/CD workflows. But running all the tests can be extremely time-consuming, and provides slow feedback to the developers.
Instead, consider dividing tests into “pre-Merge” and “post-Merge” buckets. For instance, explore how LinkedIn manages pre-merge and post-merge workflows.
Splitting the tests
There are a couple of considerations to split the tests effectively:
- The pre-merge tests should be faster to execute ensuring a fast feedback cycle for the developers
- On the other hand, the post-merge tests should be generally more stable. If these tests fail often, we end up in a constant state of failed mainline. But, we should still expect these tests to fail occasionally. If a test doesn’t ever fail, it’s not worth running!
So let’s apply that to some types of tests, these answers may vary depending on your setup but should be generally agreeable.
Code linting
Pre-merge: Linting could catch a bug early in the developer lifecycle, and is both cheap and fast to run.
Unit tests
Pre-merge: They help catch bugs at the smallest level, ensuring that each piece of the puzzle works independently.
Integration testing
Pre-merge: Integration tests verify the interactions between various modules, ensuring a cohesive and functional application.
Automated regression testing
Post-merge: Running tests to identify anything that was previously working that may have regressed. We expect these would fail less often but are still essential to maintain code health.
Performance testing
Post-merge: As changes are deployed over time, the performance of the software may be impacted, this is where performance testing is important. We do not expect every change to impact the performance, and these tests should not fail often.
User Acceptance Testing (UAT)
Post-merge: Any type of manual QA or UAT should be handled post-merge as we expect these to be extremely slow. In most cases, if we identify a failure, it is typically resolved in future releases.
Managing the split
Now that we have the tests split, we can still catch most of the issues in the development cycle, and provide fast feedback to the developer. But what happens when the post-merge tests fail?
In most cases, you coordinate with the release team to roll back the change that caused the failure or roll forward a fix manually. This manual process can be annoying and can also cause poor developer experience.
This is where MergeQueue could play an interesting role.
Understanding the MergeQueue
Before delving into the intricacies of managing pre and post-merge tests with the queue, let’s take a moment to understand the role of MergeQueue in the CI/CD pipeline. MergeQueue acts as a gatekeeper, managing code merges and orchestrating the deployment process. If you are unfamiliar with merge queues in general, here’s a good primer.
Most of the modern merge queues offer some variance of an optimistic parallel mode. In such a mode, as changes are submitted to the queue, it creates an optimistic batch that contains all queued changes including the most recent submitted one. This batch is then validated again for all the tests to ensure that it does not break the mainline before merging the PRs.
Fast forwarding merge
A small variation of this optimistic parallel mode is called a fast-forwarding merge. The main difference in the case of fast-forwarding is that you are fast-forwarding the mainline (e.g. master) to these validated commit SHAs instead of creating new commit SHAs when the PRs are actually merged post-validation.
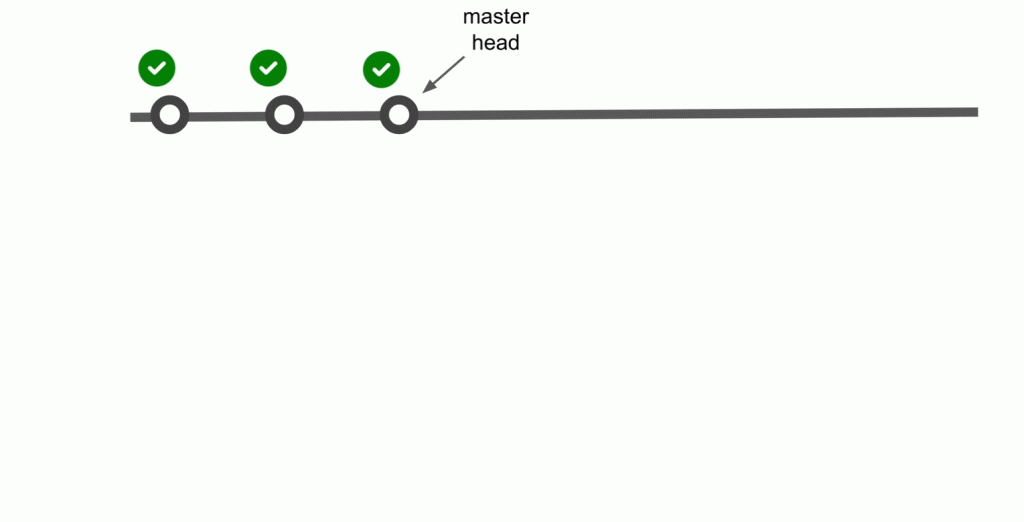
Post-merge is actually post-queue
Using the image above, you can think of the queued PRs as part of a “staging” branch. So as new commits are being added, those get “merged” into this staging. branch before they land on mainline. If we use that lens, we can run the “post-merge” test in the queue instead of running them after the changes are merged in mainline.
From the developer feedback viewpoint, the experience of “handing over” the PR to the queue is the same as merging the PR. But now, your rollbacks can be automated. Since the queue validates the changes before forwarding the mainline, any failure detected gets force pushed out.
Developer experience
As a developer, the workflow would be:
- Open a PR, run the pre-merge test, and request a code review
- Once the changes are approved and the tests pass, instead of merging the PR, they can enqueue it
- Merge Queue will create a new branch with the squash commit of changes and run the CI on it. Developers can still access this
stagingbranch if they want to access the latest codemix, knowing that it may still not have all the tests validated. - If all the tests pass, the mainline is fast-forwarded to this commit SHA, the original PR is flagged as merged.
- If any of the required tests fail, the mainline is not impacted, and the developer is notified about the failed tests and the PR remains open for the developer to fix the issue and submit again.
Behind the scenes
The queue runs all the post-merge tests, which may be slow but usually pass. The mainline is always green because the changes are completely validated before they reach mainline. You would want to configure separate test execution and validation for the PRs created by developers and the branches created by the queue. Aviator MergeQueue provides a simple branching structure to split the test execution in all the common CI platforms for efficient CI usage.
Conclusion
In one of our old posts, we also talked about the death by a thousand papercuts due to the broken mainline, but maintaining a faster feedback cycle is also critical for an improved developer experience.
Using MergeQueue to split the tests (pre-queue and post-queue) is a great way to balance both sides of the problem while improving developer productivity.









