Verification Is Not Testing. Understanding the Difference Could Save Your Codebase
AI-generated code can pass every test and still implement the wrong feature. Learn why testing and verification answer different questions, and why modern AI development needs both to catch bugs and intent mismatches.

Testing is there to answer “Does this code behave correctly?” Verification, on the other hand, answers “Does this code match what we’ve agreed to build?”
Before AI came into the picture, the human author was also the one carrying the intent, and the two questions collided into one. An AI agent has no intent, however. It just follows the prompt. So if the prompt lacks some details or is a bit unclear, it can end up writing tests that don’t just miss the point, but actually misunderstand something and treat it as correct.
There’s actually a real-world example of this. In Aviator’s intent-driven experiment, a verification agent checked 65 acceptance criteria in 6 minutes and caught 4 failures that weren’t bugs at all. They were intent mismatches, and that’s the class of failure your CI pipeline isn’t built to see.
TL;DR: Testing code means checking if it runs correctly, and the verification of code confirms that it does what has been agreed upon. They sound the same, and for a very long time, developers and testers actually treated them as the same thing. AI flipped that. Now, when an agent generates 6,000+ lines of code from a single prompt, every test can pass, even though the code is doing the wrong thing. And there’s nothing in your pipeline telling you that.
Two Similar, yet Different Questions
When you run a test suite, you see the following behavior: given X inputs, code produces Y outputs.
AI code verification asks something different: “Does this implementation match what was agreed on before writing any code?” Here, it’s not about whether a function returns the right value but whether the function itself is right.
The reference point here is an external artifact a human has approved (such as a spec with acceptance criteria), not the code’s own logic.
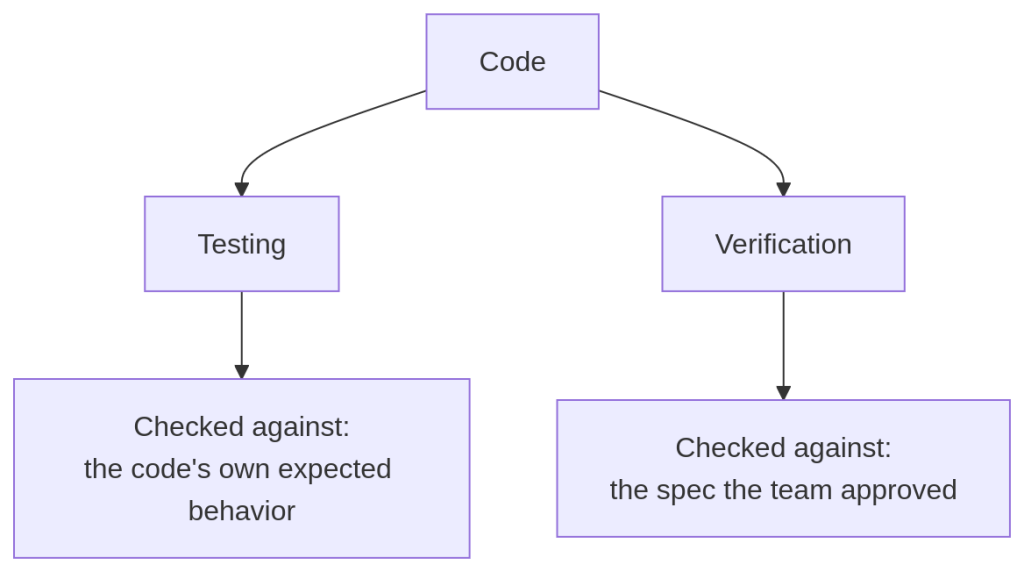
Testing vs. verification
The two don’t always line up. An agent misreading a prompt will write the wrong code, as well as the tests that confirm this wrong code works. Green checkmarks all the way!
As Ankit Jain put it, tests tell you whether the code does what the author has intended, but they can’t tell you whether that intent was the right thing to build.
The Author Carried the Intent
But how did the industry survive while treating these as one question? The answer is simple: because the intent lived in a human brain.
When an engineer wrote a feature, they knew what they meant. The ticket was vague, but the gap got filled by the person typing. Code review worked as informal verification because a reviewer could simply ask why something was done in a specific way and get the answer backed by real context.
An Agent Has No Intent, Only a Prompt
An LLM-infused agent doesn’t know what you meant (no mind-reading Neuralink features yet). But, it knows what you wrote, and it sticks to that.
If the prompt captures 90% of the intent, the agent builds 90% of the feature and fills the rest with probabilistic, yet plausible guesses. Then the agent writes tests for what it has built, including these probabilistic, yet plausible guesses. There is no person to rationalize. You can ask the agent, obviously, but you will just get a confident explanation for whatever it ended up producing.
It’s not so much that agents write buggy code. Most of what they produce runs and passes tests. The real issue is that “correct” and “what was agreed upon” split apart as soon as intent gets turned into a prompt. And since generation now outpaces review by an order of magnitude, no human has the time to read everything closely enough and actually notice these issues.
You need a mechanism that compares the implementation against the agreement itself. But this only works if the agreement exists as an explicit artifact, and that’s the core idea behind spec-driven development.
What 65 Criteria in 6 Minutes Looks Like
The engineering team at Aviator ran this test end-to-end. Engineers wrote and reviewed a detailed spec before implementation, and a human approved it. An agent then built the feature, roughly 6,000 lines, none written by hand. A second agent verified the output against the spec’s 65 acceptance criteria. The verification took 6 minutes: 60 criteria passed, 4 failed, 1 partial.
The failures were the places where the implementation did something reasonable that was not what the team had actually agreed on. Without that spec as a reference, those criteria would have shipped wrong, only to be discovered later by an unlucky user.
A human doing the same check would have taken hours. They would probably have done it only once, and their attention would start to drift by criterion 40. The agent, on the other hand, can redo it on every revision.
Verification has just gone from something that’s almost unaffordable to something you can run on every push.
Where Testing Fits
None of this makes testing optional. It still catches what verification never will: regressions, broken edge cases, performance cliffs. The point is that testing answers a narrower question, and verification is right above it.
| Testing | Verification | |
|---|---|---|
| Question | Does the code behave correctly? | Does the code match what was agreed upon? |
| Reference point | The code’s own expected behavior | A human-approved spec |
| What it catches | Bugs and regressions | Intent mismatches and scope drift |
| Blind spot | Working code that builds the wrong thing | Right thing that’s been built poorly |
| Written by | Often the same agent that wrote the code | Derived from the approved spec |
Each layer covers what the other can’t. That’s the Swiss cheese model from Ankit’s Latent Space piece: trust comes from stacking layers with different gaps so that holes don’t overlap.
But in practice, most teams are shipping with one slice while treating it like two.
What Changes in the Pipeline
Most CI/CD pipelines encode a simple assumption: tests pass, code is ready. Every gate checks behavior, but nothing checks agreement, because this used to be verified by humans. The problem is that the loop now has fewer humans and far more code. (AI-generated code, to be precise).
Verification becomes its own gate, with the spec as the reference:

From spec approval to agent implementation
Two things change:
1. A spec exists before implementation.
- The spec does not need to be heavyweight. A structured product requirements document (PRD) with acceptance criteria works.
- Reusable workflow templates mean you’re not writing stuff from scratch each time.
- The main role humans have is approving the spec.
2. Verification runs as a distinct pass/fail signal.
- Aviator Verify does this with two verification layers:
- User criteria: Submitted via MCP, generated by the agent from the spec, or written by hand
- Invariant criteria: From the team’s invariant catalog
- A failed verification means the code has deviated from the agreement. You don’t debug it immediately. First, you decide whether the code or the spec is wrong.
What Comes Next
A workflow built for AI-heavy volume requires clear ownership every step of the way. Humans own the spec: they co-author it and approve it. Tests own behavior, as they always have. Verification owns agreement (checking implementation against acceptance criteria on every revision).
Basically, human review shrinks to spec approval upstream. No one is expected to read 6,000 lines of agent-generated output anymore. Aviator Verify is built for that missing layer: deterministic checks of AI-generated code against your anti-AI slop registry and human-approved acceptance criteria. On every revision, with an audit trail.
If your pipeline can answer, “Does it run?” but not, “Is it what we agreed upon?”, sign up for early access.
Frequently Asked Questions (FAQ)
Does verification equal more testing?
No. The reference point differs. Tests check code against expected behavior; verification checks it against an independent spec.
Can better tests catch intent mismatches?
Not when the same misunderstanding has produced both the code and the tests.
Does writing specs slow everything down?
A structured product requirements document (PRD) with acceptance criteria is enough, and agents can draft it. One approval replaces hours of line-by-line diff reading.
Where does human code review go?
Upstream and on demand. Humans approve the spec before implementation and resolve verification failures after.