How do git commits actually work?


Git is often one of the first tools developers learn to use, but it also is a black box of ~magic~ to many for that same reason. However, by learning about how Git operates at a lower level, you’ll more intuitively understand what is happening when you run commands like and git cherry pick.
Whether you’re a Git novice or an experienced developer, this post will provide valuable insights into the inner workings of the world’s most popular and powerful version control system.

Git is a content-addressable filesystem
In other words, at the heart of Git lies a straightforward key-value data store. And, as its name suggests, it stores and accesses values (the data/ content) with keys (the content address).
So what exactly do those keys and values look like? Hashes of the values, mostly.
More specifically, the keys are just SHA-1 hashes of the values. So then what are the values / the content of which we are taking the hash? To understand that, we have to learn more about Git objects
Objects
Git objects are the fundamental building blocks of a Git repository, used to store data such as commits, files, and directories.
Blob objects
A blob, short for “binary large object,” is a type of Git object that stores the contents of a file as a snapshot in the Git object database.
To generate the hash for a blob object, Git calculates the SHA-1 hash of the file contents. This hash is later used to locate the blob object in the Git object database (.git/objects). When you make changes to a file and commit the changes, Git stores the new contents of the file (in its entirety, not just the diff) as a new blob object with a new SHA-1 hash. This allows Git to track the changes to the file over time and manage the file’s history.
If there existed a JSON representation of a blob object, it could look something like this:
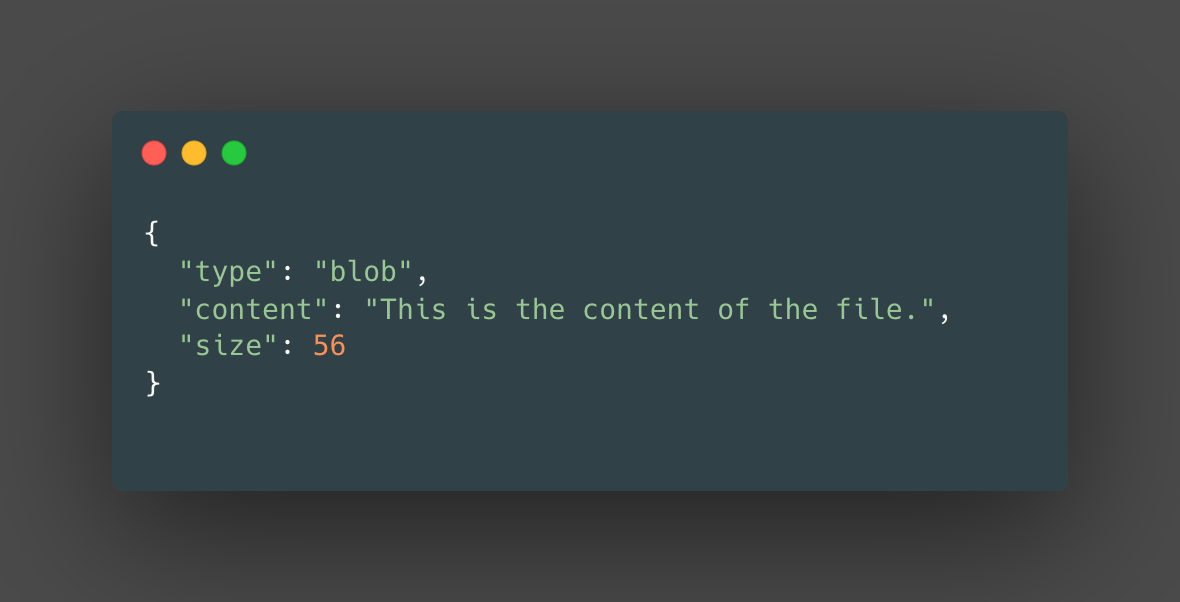
A couple things to note here First, git objects are not stored as JSON in Git. Second blob objects do not store the name of the file in it and only stores the contents of a file.
So then, how do we match a file with its respective contents?
With tree objects!
Tree objects
A tree object is a type of Git object that represents the contents of a directory in a Git repository. It’s an abstraction that enables Git to store a collection of files and directories together in a single object.
It does this by including a list of the files and directories contained in the directory, along with the SHA-1 object name (a unique identifier) of each file or directory. This creates a mapping between the names of the files and directories to their corresponding hashes.
To calculate the SHA-1 hash of a tree object, Git follows these steps:
Git creates a list of all the files and directories contained in the tree, along with their mode, type, and SHA-1 object name.

Git then sorts the list of files and directories alphabetically by name and creates a tree object that looks something like this:
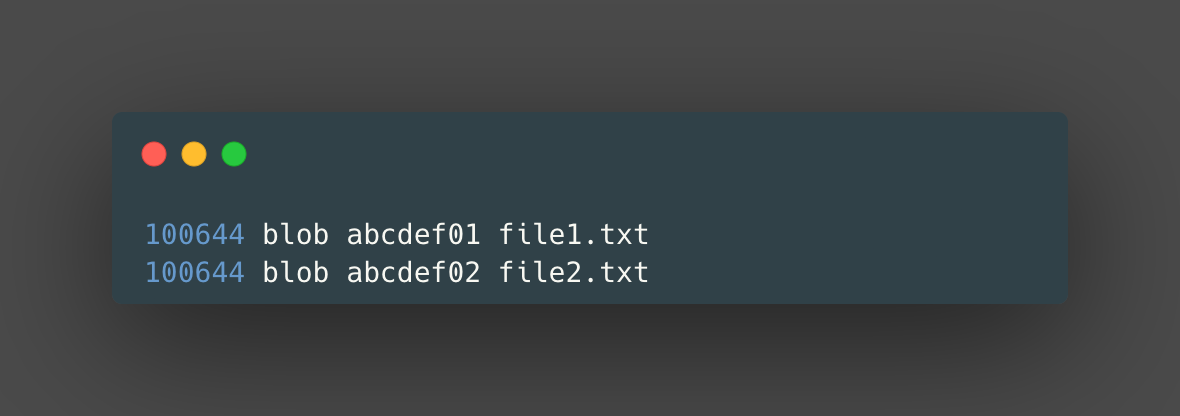
In Git, the file mode specifies the type and permissions of a file. The number 100644 indicates that the file is a normal, non-executable file. The blob keyword indicates that the following hash refers to a blob object. The hash abcdef01 is the SHA-1 object name of the blob object for the file file1.txt.
For each file or directory in the list, it retrieves the SHA-1 object name of the file or directory. Then, it concatenates the object names and file or directory names into a single string. For example:
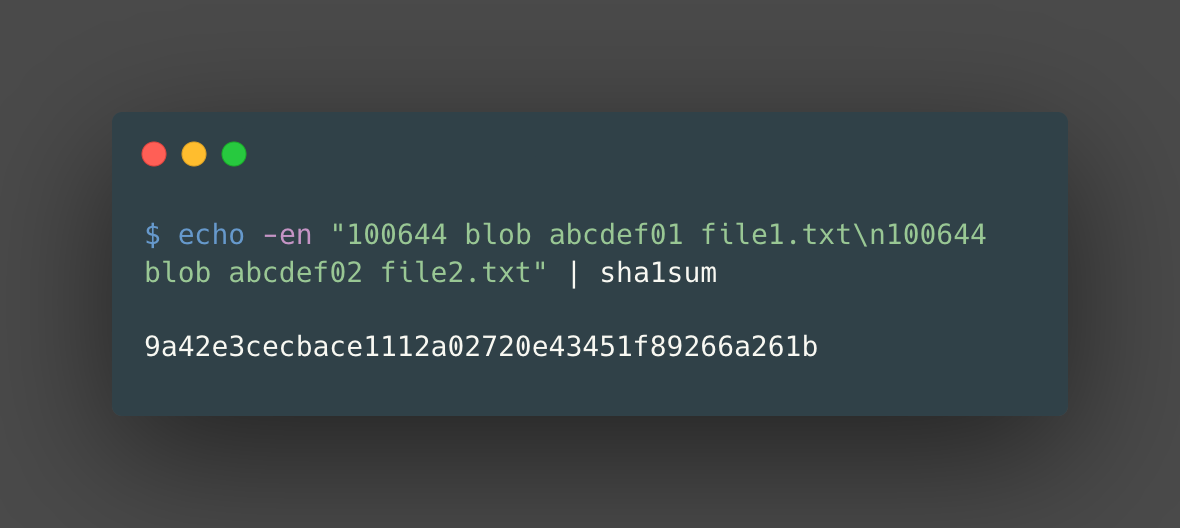
This hash, 9a42e3cecbace1112a02720e43451f89266a261b, would be the hash of the tree object.
This is just a general high-level overview of how Git creates an SHA-1 hash of a tree object.
A visual representation of a JSON tree object might look something like this:
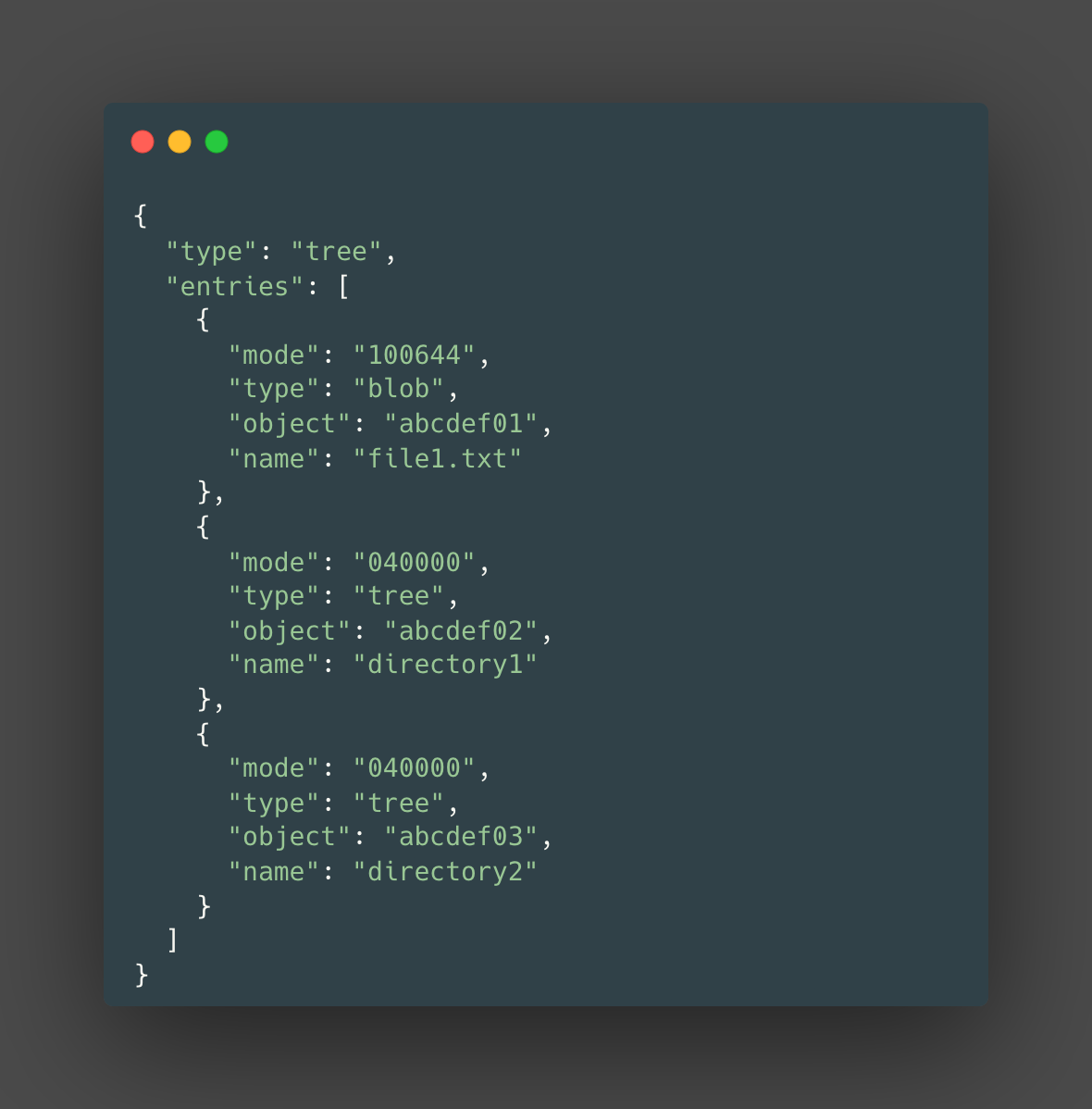
Commit objects
A commit object is a type of Git object that represents a snapshot of the repository at a particular point in time. It stores a reference to a tree object, which represents the state of the repository’s directories and their respective files at the time of the commit, as well as a reference to one or more parent commit objects. Commit objects also include metadata such as the commit message, author, and timestamp.
Commit objects are created when you run the git commit command, and they form a linear chain of commits in the repository’s history. Each commit object is linked to its parent(s) through a reference, creating a linked list of commits.
If there existed a JSON representation of a commit object, it would look something like the following:
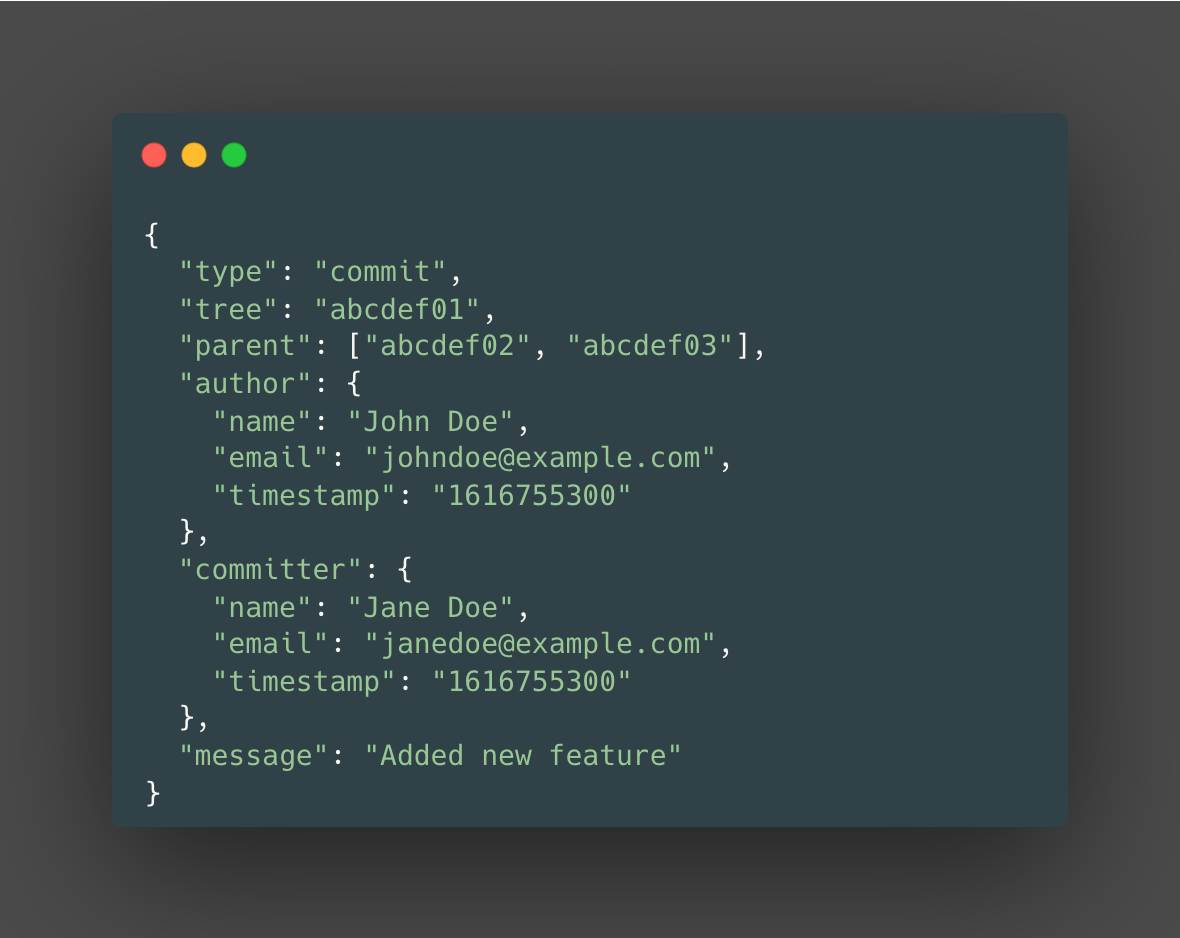
Example
Now that we’ve learned about Git objects, let’s take a look at an example to actually see the inner workings of git using some plumbing commands!
To follow along, set up a demo-repo and a file called test.txt with “test content” inside. Let’s also go ahead and add that to our staging area, which will generate a blob object for the file, test.txt.
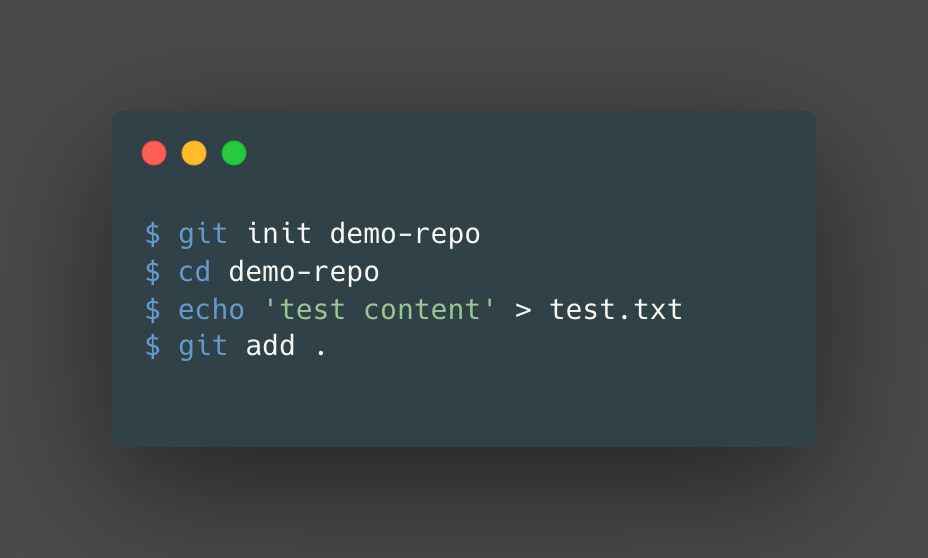
When we added the file to our staging area, we essentially took a snapshot of the contents of test.txt. To take this snapshot, we create a blob object and generate a SHA-1 hash of the contents of the file, test.txt, for the key.
Now, if you run “find .git/objects -type f” in the command line, it’ll come up with a file path that resembles a SHA-1 Hash — because that’s exactly what it is!
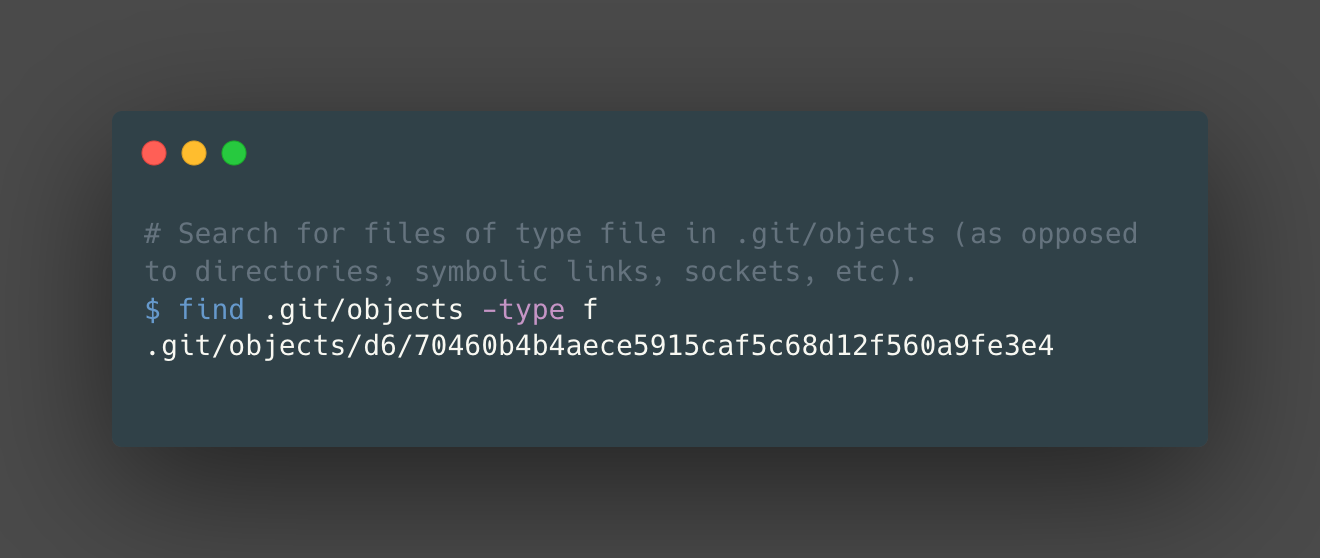
Note: Notice that Git split the hash into d6 & 70460… — Git names the subdirectory with the first 2 characters of the SHA-1, and the filename is the remaining 38 characters.
To check the value (or the content of the .git/object that we just found), we can use “git cat-file -p <HASH>”. The git cat-file command will display the contents of a git object, such as a blob in this example.
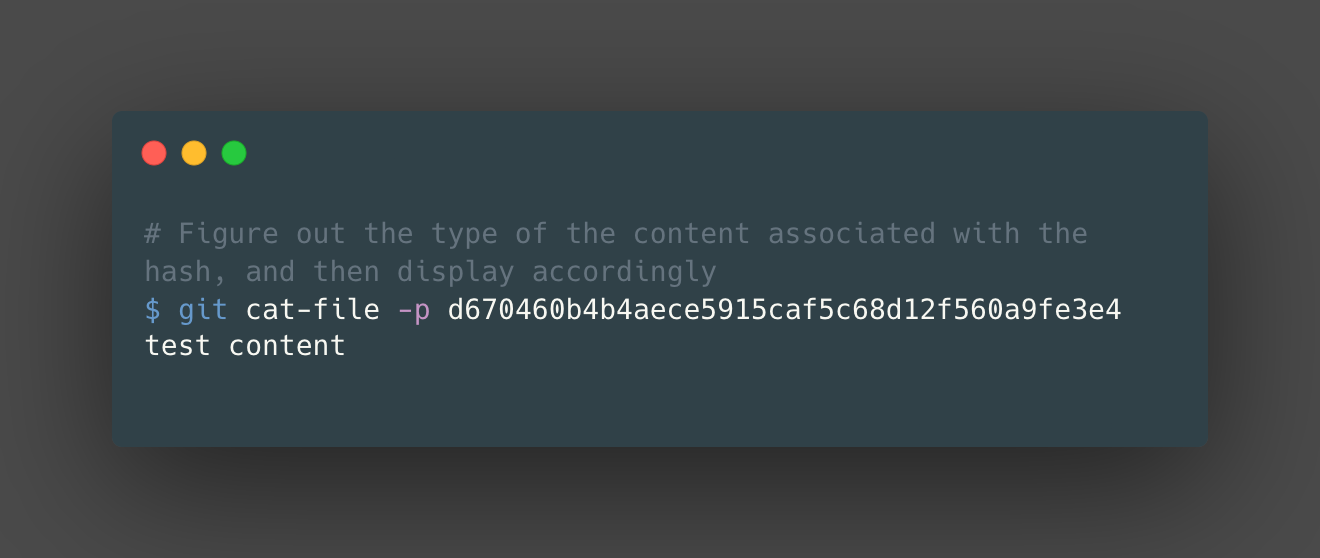
In this example, we are operating at the lowest level of abstraction (tracking only files, not directories etc), so we are just taking the SHA-1 of files and creating blob objects. Can we now create a tree object?
Of course! Recall that a commit object is merely a reference to a tree object. So, if we go ahead and “git commit” our staged changes, we’ll effectively not only create a tree object, but also a commit object!
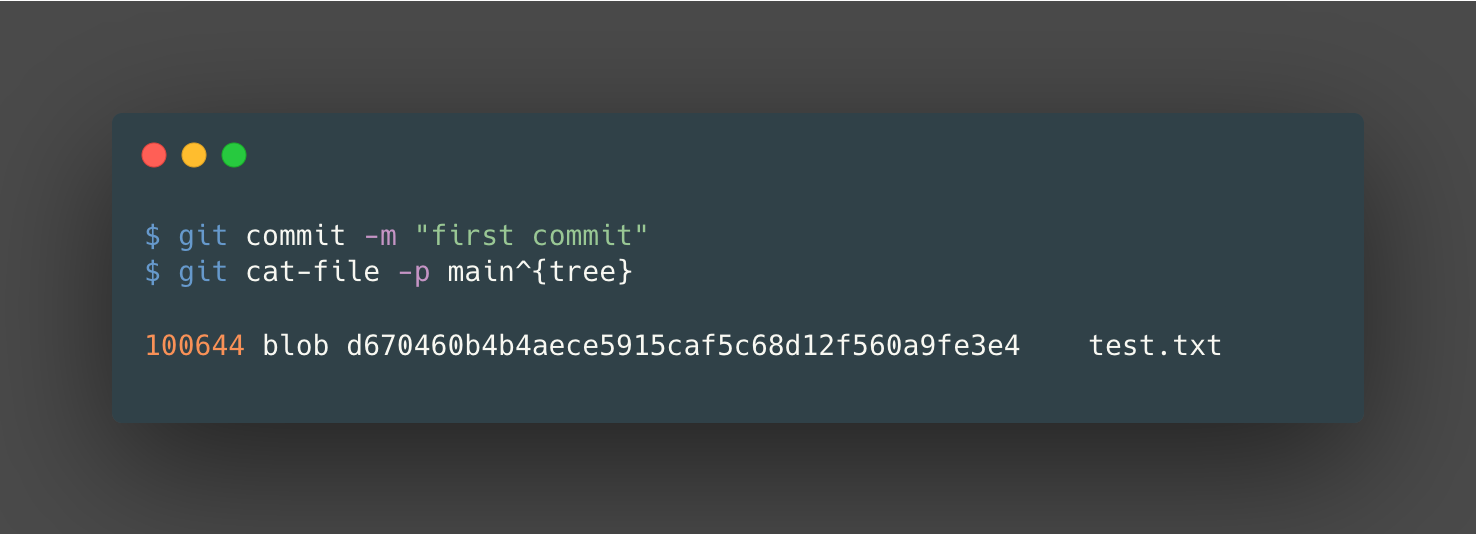
Here, we re-use the git cat-file command to explore the tree object that’s pointed to by the latest commit object on the main branch currently. Then, to explore the commit object that is pointing to the tree object, we can use git rev-parse to first find the hash of the latest commit on the main branch:
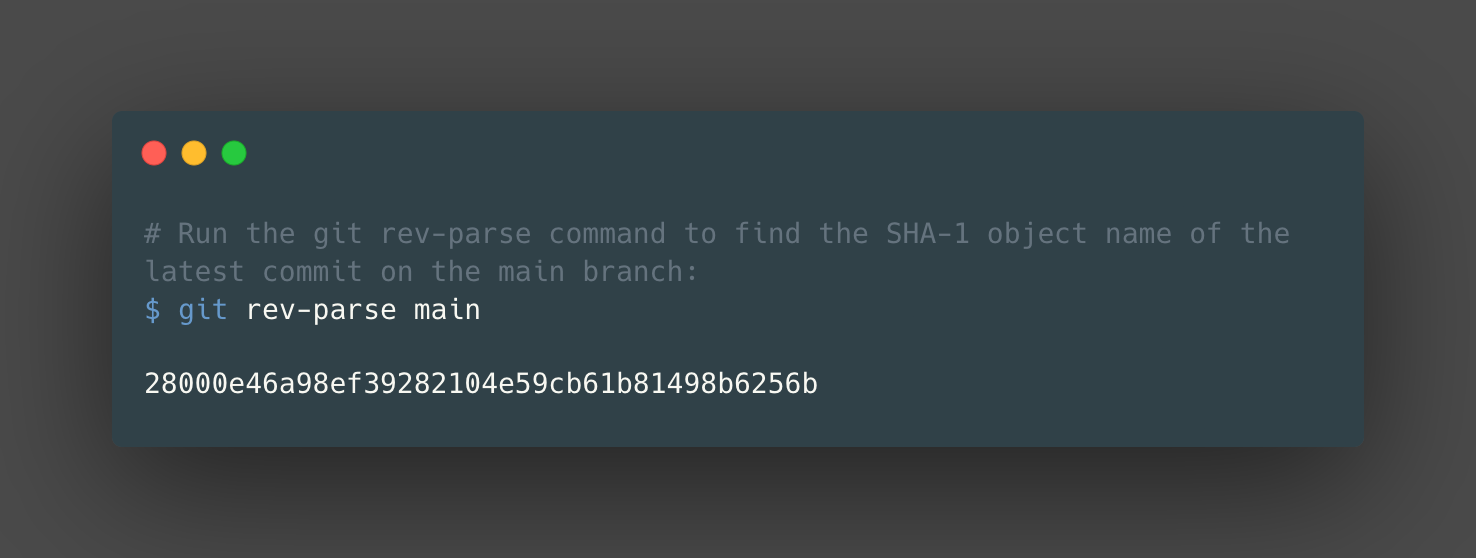
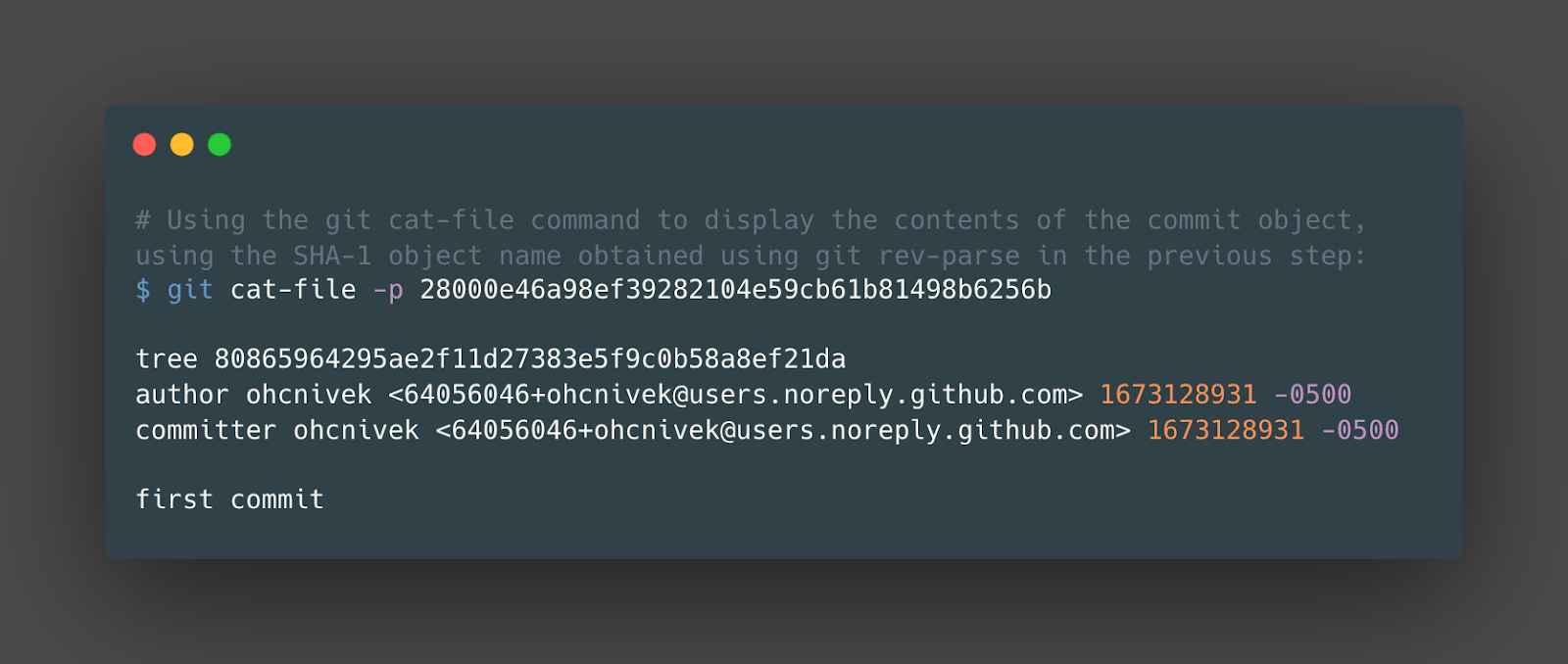
Then we can use the git cat-file command again to display the contents of the commit object, using the SHA-1 object name obtained in the previous step:
Finally, let’s list all of the git objects in our .git/objects folder by:
As we expected, we see the 3 git objects we’ve explored using git plumbing commands: d6/704.. (blob), 80/865…(tree), 28/000… (commit). We can double-check these via the hashes we found in the previous steps.
Commits are snapshots, not diffs
In conclusion, rather than a series of changes or diffs, commits in Git are snapshots of the repository at specific points in time as seen in the “snapshot” design of blob objects & its key-value store design.
As we saw, this design choice allows Git to store the entire history of a repository efficiently, without having to track the changes (or diffs) made to each file individually.
Having rebuilt (or built for the first time) our mental models of how git commits actually work, we’ll be able to more effectively use this powerful tool in our daily work to supercharge development and make better decisions while building workflows for our teams!
Aviator: Automate your cumbersome merge processes
Aviator automates tedious developer workflows by managing git Pull Requests (PRs) and continuous integration test (CI) runs to help your team avoid broken builds, streamline cumbersome merge processes, manage cross-PR dependencies, and handle flaky tests while maintaining their security compliance.
There are 4 key components to Aviator:
- MergeQueue – an automated queue that manages the merging workflow for your GitHub repository to help protect important branches from broken builds. The Aviator bot uses GitHub Labels to identify Pull Requests (PRs) that are ready to be merged, validates CI checks, processes semantic conflicts, and merges the PRs automatically.
- ChangeSets – workflows to synchronize validating and merging multiple PRs within the same repository or multiple repositories. Useful when your team often sees groups of related PRs that need to be merged together, or otherwise treated as a single broader unit of change.
- FlakyBot – a tool to automatically detect, take action on, and process results from flaky tests in your CI infrastructure.
- Stacked PRs CLI – a command line tool that helps developers manage cross-PR dependencies. This tool also automates syncing and merging of stacked PRs. Useful when your team wants to promote a culture of smaller, incremental PRs instead of large changes, or when your workflows involve keeping multiple, dependent PRs in sync.


