How to Manage Code in a Large Codebase

TL;DR
- Organize large codebases using feature-based or layer-based structures to enhance maintainability and scalability. Feature-based structures align with product functionality, making onboarding easier.
- Use Trunk-Based Development with short-lived branches for faster merges and reduced integration issues. Alternatively, GitFlow can help manage tightly controlled releases in regulated environments.
- Leverage incremental builds, caching, and parallel testing to speed up CI/CD pipelines, ensuring rapid releases without sacrificing quality.
- Enforce code quality through automated linting, static analysis (like SonarQube), and code reviews with tools like Husky, Prettier, and ESLint to catch issues early.
- Use tools like Nx for monorepo management, Aviator for merge orchestration, and Bazel for efficient builds to handle growing teams and complex codebases with minimal friction.
We’ll walk through a real-world example of scaling a React + Node.js monorepo and conclude with best practices and decision-making tips for choosing the right approach for your team.
Managing a large codebase can feel overwhelming, even for seasoned developers.
The scale of the challenge becomes apparent when looking at the numbers: one study of 39 private production codebases found that low-quality code contains 15 times more defects, takes 124% longer to resolve issues, and leads to up to 9 times slower maximum cycle times compared to higher-quality code (arXiv). In open-source projects, roughly 20% of issue types account for 80% of technical debt, with debt often lingering for long periods, especially after major milestone releases (arXiv).
Security concerns amplify these challenges: automated analyses of large codebases have revealed over 165,000 vulnerabilities, including ~53,000 high-severity and ~107,000 medium-severity issues. Meanwhile, Gartner notes that organizations that actively manage technical debt can achieve at least 50% faster service delivery (Gartner).
In this blog post, we’ll explore practical strategies for managing code at scale, covering how to structure and maintain a large codebase, integrate effective branching strategies, adopt CI/CD practices that improve release velocity, enforce quality through reviews and static analysis, and tackle technical debt systematically.
The Challenges of Large Codebases
As software systems grow in complexity, maintaining a large codebase becomes increasingly challenging. What starts as a clean and modular architecture can quickly become cumbersome due to feature creep, legacy components, and inconsistent development practices. Over time, this leads to slower release cycles, unpredictable defects, and difficulty onboarding new developers.
A recent analysis of over 1 billion lines of code revealed some concerning trends:
- Over 1 million code quality issues were identified across various projects, highlighting the prevalence of defects in large codebases.
- More than 165,000 security vulnerabilities were detected, including approximately 53,000 high-severity and 107,000 medium-severity issues.
In enterprise-scale applications, these challenges are amplified.
With hundreds of contributors across distributed teams, maintaining consistency and quality becomes a central engineering challenge. SaaS companies pushing updates multiple times per day face the pressure of rapid development cycles, leaving little room for manual oversight. Open-source projects, with their
In this article, we’ll explore effective strategies for managing large codebases, including best practices for code quality enforcement, branching models, CI/CD pipelines, and tools like Aviator, Nx, and GitHub Actions.
Structuring a Large Codebase for Scalability
A well-structured codebase is the foundation of maintainability. As teams and features scale, disorganized repositories lead to slower iteration, merge conflicts, and increased cognitive load for developers. Choosing the right structure, both in terms of folder hierarchy and repository strategy, helps prevent these issues and supports sustainable growth.
Modular Architecture & Folder Structure
In large codebases, modular architecture ensures that individual components are decoupled, reusable, and testable. Two common approaches are feature-based and layer-based organization.
- Layer-based organization separates files by their role in the application, controllers, services, models, and utilities are grouped into their respective directories. While this structure works well for smaller teams, it can become harder to navigate as the codebase scales since related logic is scattered across different layers.
If we adopt the layer-first approach, our project structure may look like this:
‣ lib
‣ src
‣ presentation
‣ feature1
‣ feature2
‣ application
‣ feature1
‣ feature2
‣ domain
‣ feature1
‣ feature2
‣ data
‣ feature1
‣ feature2- Feature-based organization groups files by functionality rather than technical type. For example, a user/ directory may contain the controller, service, and UI elements for handling user-related logic. This method aligns closely with product features and simplifies onboarding for developers working on specific functionality.
Using the same example as above, we would organize our project like this:
‣ lib
‣ src
‣ features
‣ feature1
‣ presentation
‣ application
‣ domain
‣ data
‣ feature2
‣ presentation
‣ application
‣ domain
‣ dataTo maintain clarity at scale, teams often enforce boundaries using Domain-Driven Design (DDD). DDD defines clear ownership of domains (e.g., billing, authentication, notifications) and encapsulates their logic within bounded contexts. This avoids cross-domain coupling and keeps dependencies predictable.
Example: Organizing a React + Node.js Monorepo
/apps
/web-app # React frontend
/api-service # Node.js backend
/packages
/ui-components # Shared React components
/utils # Reusable utility functions
/shared
/config # Environment configs and constants
/types # Shared TypeScript definitionsThis layout promotes modularity, ensures separation of concerns, and allows parallel development across teams without constant merge conflicts.

Monorepo vs Polyrepo: Choosing the Right Model
When managing multiple services or applications, teams must decide between a monorepo and a polyrepo structure.
Monorepo: Unified Codebase at Scale
Netflix’s engineering team has embraced a distributed monorepo approach, where all source code resides in a single repository. This strategy enables efficient cross-project refactoring and enforces consistent tooling across services. However, to manage the scale of their codebase, Netflix employs advanced techniques to ensure true continuous integration.
To address the challenges of large-scale monorepos, Netflix has implemented a distributed repository model. This model allows for the logical separation of codebases while maintaining a unified view for developers. By using tools like Bazel for build optimization and Spinnaker for continuous delivery, Netflix ensures that changes are tested and deployed efficiently across their vast infrastructure.
This approach simplifies dependency management and enhances developer productivity by reducing build times and enabling faster feedback loops. It exemplifies how large-scale organizations can leverage monorepos to maintain agility and consistency in their development processes.
Polyrepo: Distributed Repositories for Autonomy and Scalability
Several large-scale organizations, including Amazon, Uber, and Tesla, have adopted polyrepo architectures, where each project or service resides in its own repository. This strategy allows teams to work independently, isolate failures, and deploy services without impacting unrelated codebases.
To handle the complexities of multiple repositories at scale, these organizations implement robust CI/CD orchestration and dependency management. For example, Amazon maintains separate pipelines for each microservice, enabling automated testing, build verification, and deployment per repo. Uber follows a similar approach, combining repository isolation with tooling to ensure consistent integration and fast feedback loops.
The polyrepo model provides key benefits: it allows teams to scale services independently, enforce granular access controls, and adopt customized workflows per repository. However, managing shared libraries and coordinating cross-repo refactoring requires careful versioning and release strategies, often supported by tools like Lerna, Gradle, or Bazel for dependency handling and build efficiency.
Tooling Impact
To handle scale effectively, modern build tools like Aviator, Nx, Turborepo, and Bazel offer features like incremental builds, task caching, and dependency graph visualization. These tools help mitigate the performance drawbacks of large monorepos while preserving their collaboration benefits.
Version Control & Branching Strategies for Large Teams
Maintaining stability in large, distributed codebases requires more than just picking a branching model, it’s about aligning branching, CI/CD pipelines, and developer workflows to minimize friction. Teams like Netflix, operating across thousands of services, emphasize short-lived integration-focused branches over long-lived isolation, enabling rapid, low-risk deployment.
Short-Lived Branches & Trunk-Based Development in Practice
At scale, Trunk-Based Development isn’t just about merging into main; it’s a framework for continuous integration, rapid feedback, and automated validation:
- Frequent Integration: Developers merge multiple times per day, keeping branch divergence minimal. This reduces merge conflicts and ensures the mainline remains deployable.
- Pipeline-First Enforcement: Each commit triggers a pipeline, spanning linting, unit, integration, and service-level tests, before merge approval. Aviator’s pipeline orchestration ensures that these checks are consistently enforced across all services, even in monorepo or hybrid repo setups.
- Feature Management: Feature toggles allow teams to merge incomplete work safely, reducing long-lived branches without slowing product delivery. Canary deployments and automated observability feed into this strategy, letting teams detect issues before they impact production.
This approach scales well for teams delivering multiple deploys per day, maintaining velocity without sacrificing safety, and reducing manual merge overhead.
Coordinated Release Strategies for Complex Environments
Even in organizations favoring TBD, certain contexts, regulatory compliance, multi-tenant enterprise deployments, or multi-version software, necessitate controlled release coordination. Instead of abruptly introducing GitFlow, teams often adopt hybrid practices:
- Short-lived integration branches feed into staging or release branches, where final validation occurs.
- Hotfix workflows exist for emergency patches, orchestrated via CI/CD pipelines that validate changes against production-like environments before merging back into main.
- Release management tooling (Aviator integrated pipelines, feature toggles, semantic versioning automation) ensures that these hybrid flows remain predictable without slowing daily development.
Code Quality, Reviews, and Standards
Maintaining code quality in large codebases goes far beyond simple formatting, it’s about maintaining consistency, reducing technical debt, and preventing regressions at scale. Effective review workflows and enforceable standards ensure that every commit strengthens the system rather than introducing new risks.
Enforcing Linting & Static Analysis
Large codebases can quickly become inconsistent if linting and static analysis aren’t part of the development workflow. ESLint and Prettier handle formatting and style enforcement, ensuring that teams follow consistent conventions without manual intervention. For deeper static analysis, tools like SonarQube or GitHub’s CodeQL scan for potential vulnerabilities and maintainability issues before changes reach production.
Git hooks via Husky can run pre-commit checks to catch formatting issues, linting errors, or security vulnerabilities early in the cycle. Aviator can complement these checks by automating build verification and integrating lint/test gates into merge pipelines, ensuring that no low-quality code slips through.
Managing Pull Requests & Review Workflows
Pull requests (PRs) are where most quality enforcement happens, but their size and review process heavily affect engineering velocity. Small, focused PRs are easier to review, reducing the cognitive load for reviewers and cutting down lead time for merging. Large PRs, while sometimes unavoidable for architectural changes, can increase the risk of regressions and delay releases.
Tools like Reviewable provide structured review workflows, while CodeCov ensures test coverage remains consistent across changes. GitHub CodeSpaces allows reviewers to spin up isolated environments for complex changes. Aviator adds value here by automating PR workflows, merging only after all tests, linting checks, and required approvals pass, while minimizing human bottlenecks in large teams.

Real Example: Refactoring a Node.js API Layer with Minimal Downtime
Consider a Node.js API where database queries are embedded directly in route handlers, a common anti-pattern in fast-growing projects. The first step is extracting query logic into a repository layer, ensuring test coverage for the new abstraction. Next, a service layer can be introduced to handle business logic, leaving the route handler as a thin orchestration layer.
// Legacy route (before refactoring)
app.get('/users/:id', async (req, res) => {
const user = await db.query(`SELECT * FROM users WHERE id = ${req.params.id}`);
res.json(user);
});
// After refactoring: repository pattern
import { getUserById } from './repositories/userRepository.js';
app.get('/users/:id', async (req, res) => {
const user = await getUserById(req.params.id);
res.json(user);
});This progressive refactoring keeps endpoints functional throughout the migration while gradually improving structure. Once repositories and services are fully in place, the API becomes easier to maintain, test, and extend, without a full system rewrite.
Best Practices for Managing Large Codebases: Insights from Google
1. Onboarding and Developer Productivity
At Google, the scale of the codebase necessitates efficient onboarding processes. New developers are introduced to the codebase through comprehensive documentation integrated within the code itself. Tools like Google’s Agent Development Kit (ADK) facilitate the creation of a knowledge base directly from the repository, enabling developers to understand project conventions and dependencies without extensive external resources.
Additionally, Google’s internal tools automate routine tasks, reducing cognitive load and allowing developers to focus on high-value work. This automation is complemented by a culture that emphasizes code readability and maintainability, ensuring that new team members can quickly become productive.
2. Long-Term Codebase Stability
To maintain the integrity of their vast codebase, Google employs a combination of disciplined practices and robust tooling. Regular refactoring is institutionalized through scheduled sprints, preventing the accumulation of technical debt and ensuring that the codebase evolves in a controlled manner.
Version pinning in package managers is standard practice, ensuring that dependencies are consistent across environments. This is enforced through continuous integration pipelines that validate changes against a suite of tests, providing immediate feedback to developers and maintaining stability across the codebase .
Moreover, Google measures technical debt through quarterly engineering surveys, gathering insights from engineers about which areas of the codebase are hindering their work. This data-driven approach allows for targeted interventions and prioritization of refactoring efforts .
Example Walkthrough: Scaling a React + Node.js Monorepo
0) Prerequisites (one-time)
- Install: Node.js 18+ (or 20+), Git.

Package manager: Using pnpm for speed.
corepack enable
corepack prepare pnpm@latest --activate- VS Code extensions:
- ESLint (dbaeumer.vscode-eslint)
- Prettier (esbenp.prettier-vscode)
- Nx Console (nrwl.angular-console) – handy GUI for Nx commands.
- GitHub repo ready (we’ll push later).
Tip: Nx has first-class generators for React and Node. We’ll use @nx/react:application and @nx/node:application.
1) Create the workspace
Open VS Code → Terminal (Ctrl+` ) and run:
# Create empty folder and init git
mkdir large-codebase && cd large-codebase
git init
# Create an Nx workspace (standalone, TS)
pnpm dlx create-nx-workspace@latest --name=large-codebase --preset=apps --pm=pnpm
cd large-codebaseThis creates a minimal Nx workspace with TypeScript config and basic scripts.
2) Generate apps: React (Vite) + Node API (Express)
# React app (Vite under the hood)
pnpm nx g @nx/react:application web --bundler=vite --style=css
# Node.js API (Express)
pnpm nx g @nx/node:application api --framework=express- React app will land in apps/web.
- Node API will land in apps/api.
- Nx wires basic build/test targets for both. (You can see them in project.json per app, or via Nx Console.)
3) Add shared libraries (modularity from day one)
We’ll keep UI and utilities reusable and version-controlled.
# Shared React UI library
pnpm nx g @nx/react:library ui --directory=packages --bundler=none
# Shared TS utils library
pnpm nx g @nx/js:library utils --directory=packages --unitTestRunner=jest
Your repo layout now looks like:
apps/
api/
web/
packages/
ui/
utils/Nx automatically sets path aliases in tsconfig.base.json (e.g., @large-codebase/utils). Import from apps like:
import { something } from '@large-codebase/utils';4) Wire the dev experience (VS Code)
4.1 .vscode/settings.json
Create:
{
"editor.formatOnSave": true,
"files.eol": "\n",
"editor.defaultFormatter": "esbenp.prettier-vscode",
"eslint.validate": ["javascript", "typescript", "typescriptreact", "json"]
}4.2 .vscode/launch.json (debug both)
Create:
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "API: dev",
"runtimeExecutable": "pnpm",
"runtimeArgs": ["nx", "serve", "api"],
"cwd": "${workspaceFolder}",
"console": "integratedTerminal"
},
{
"type": "pwa-chrome",
"request": "launch",
"name": "Web: dev",
"url": "http://localhost:5173",
"webRoot": "${workspaceFolder}/apps/web"
}
]
}Run API and Web side by side via Run and Debug.
5) Connect the web app to the API (dev proxy)
For Vite, add a proxy in apps/web/vite.config.ts so the React dev server can hit the API seamlessly:
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
export default defineConfig({
plugins: [react()],
server: {
port: 5173,
proxy: {
'/api': {
target: 'http://localhost:3000', // Express default from Nx
changeOrigin: true
}
}
}
});In apps/api/src/main.ts (Express), add a quick route:
import express from 'express';
const app = express();
app.get('/api/hello', (_req, res) => {
res.json({ message: 'Hello from API' });
});
const port = process.env.PORT || 3000;
app.listen(port, () => console.log(`API running at http://localhost:${port}`));In apps/web/src/App.tsx:
import { useEffect, useState } from 'react';
export default function App() {
const [msg, setMsg] = useState('...');
useEffect(() => {
fetch('/api/hello')
.then((r) => r.json())
.then((d) => setMsg(d.message))
.catch(() => setMsg('API error'));
}, []);
return <h1>{msg}</h1>;
}Try it:
pnpm nx serve api
# new terminal
pnpm nx serve web6) Linting, formatting, and hooks (quality gates)
Install Prettier, ESLint (if not already), Husky, and lint-staged:
| pnpm add -D prettier eslint lint-staged husky pnpm dlx husky install |
Add to package.json:
{
"lint-staged": {
"*.{js,ts,tsx,css,md,json}": [
"eslint --fix --max-warnings=0",
"prettier --write"
]
},
"scripts": {
"prepare": "husky install"
}
}Create pre-commit hook:
pnpm dlx husky add .husky/pre-commit "pnpm dlx lint-staged"| pnpm dlx husky add .husky/pre-commit “pnpm dlx lint-staged” |
Now staged files are auto-fixed before every commit.
7) Speed at scale: incremental builds + caching
Nx computes a project graph and runs tasks only where needed:
Locally, use:
# Build only what changed since main
pnpm nx affected --target=build --base=origin/main --head=HEAD
# Run tests for only what changed
pnpm nx affected --target=test --base=origin/main --head=HEAD- On CI, we’ll wire the same logic (next step). (Nx’s “affected” docs show best practices for base/head and ignore lists.)
8) CI with GitHub Actions (parallel + cached)
Create .github/workflows/ci.yml:
name: CI
on:
pull_request:
push:
branches: [main]
jobs:
build-test:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'pnpm'
- name: Install pnpm
run: corepack enable && corepack prepare pnpm@latest --activate
- name: Install deps
run: pnpm install --frozen-lockfile
# Computes NX_BASE/NX_HEAD for reliable affected runs on PRs & pushes
- name: Set Nx SHAs
uses: nrwl/nx-set-shas@v4
- name: Print Affected
run: pnpm nx print-affected
- name: Build affected (parallel)
run: pnpm nx affected --target=build --parallel=4
- name: Test affected (parallel + cache)
run: pnpm nx affected --target=test --parallel=4
- name: Lint affected
run: pnpm nx affected --target=lint --parallel=4- nrwl/nx-set-shas sets NX_BASE/NX_HEAD for accurate affected ranges on PRs & pushes.
- This mirrors Nx’s official CI recipe for GitHub Actions.
Optional: add E2E (Cypress/Playwright) as –target=e2e on affected projects.
9) Monorepo scaling: keep boundaries tight
As the repo grows, keep code split into feature-oriented libraries and evolve with Nx generators:
# New feature library, e.g., auth domain
pnpm nx g @nx/js:library auth --directory=packages --unitTestRunner=jest
# Move a lib if needed (Nx updates imports & paths)
pnpm nx g @nx/workspace:move --project=packages-utils packages/core-utils10) Add Aviator MergeQueue (stable main, high velocity)
Aviator’s MergeQueue serializes/parallelizes merges in a way that keeps your main branch green by testing PRs against the current base and merging only when checks pass. Connect the GitHub App, select repos, and enable rules for your branch.
Quick setup (high level):
- Install the Aviator GitHub App and authorize your repo.
- Follow the onboarding flow to connect to the Aviator GitHub app, authorize one or more repositories that you want to automate.
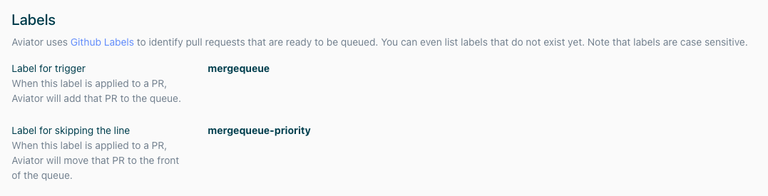
- Select the repository on the Repositories page to configure the rules. This will take you to the Basic Configuration page to customize some basic settings.

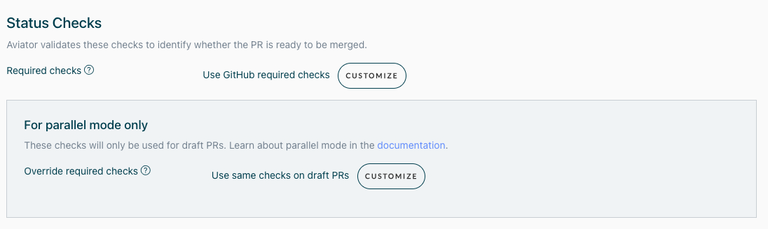
- On this page, you will see two GitHub labels. These labels are the most common ways for Aviator MergeQueue to interact with your pull requests. The default trigger label is called mergequeue.
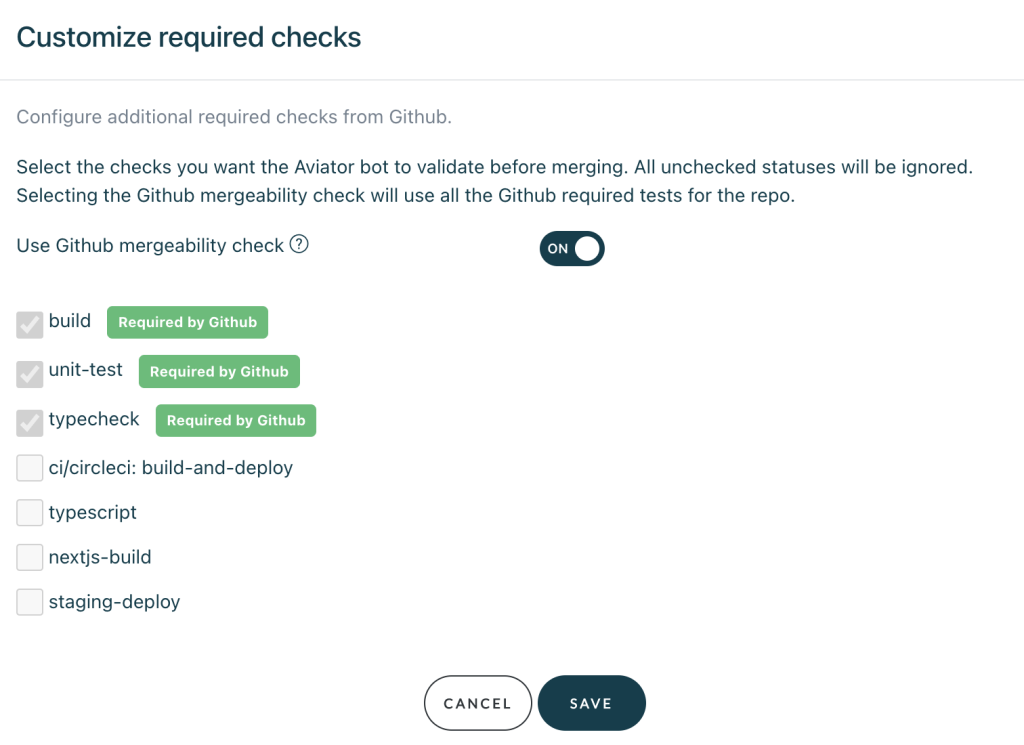
- Verify the required status checks are set correctly. By default, Aviator sync the required checks from GitHub branch protection rules, but you can customize them here.
- That’s it. You are ready to go. Now when a PR is ready, tag the PR with the trigger label mergequeue defined above. Let the Aviator bot handle the verification and merging the PR.
- Dev workflow: label PR ready-to-merge (or follow your rule); Aviator queues, validates against the latest base, and merges if green.
Why here? It complements Nx “affected” CI by eliminating broken-main incidents when many PRs land concurrently. (If you prefer GitHub’s native merge queue, you can mix it with Nx too.)
11) Commit, push, and try a full PR cycle
git add .
git commit -m "chore: bootstrap Nx monorepo with web+api and shared libs"
git branch -M main
git remote add origin <your-repo-url>
git push -u origin mainOpen a feature branch:
git add .
git commit -m "chore: bootstrap Nx monorepo with web+api and shared libs"
git branch -M main
git remote add origin <your-repo-url>
git push -u origin main
- Open PR → watch CI run Nx “affected” steps.
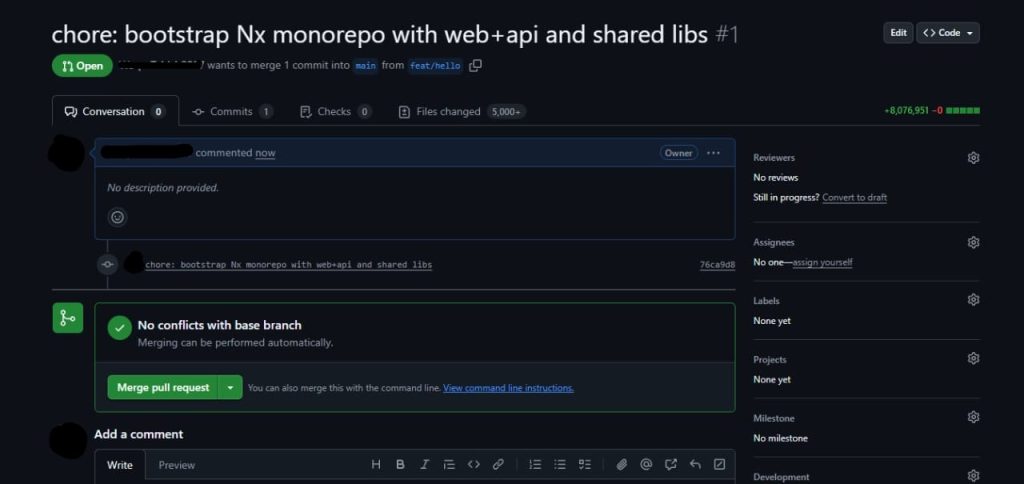
- Mark ready; Aviator MergeQueue handles safe merging to main.
Conclusion
Managing a large React + Node.js codebase requires more than just good coding practices; it demands a structured approach to branching strategies, CI/CD pipelines, automated testing, and ongoing refactoring. By leveraging tools like Aviator for CI orchestration, Nx for incremental builds, and SonarQube for static analysis, teams can maintain velocity while ensuring code quality and long-term maintainability. The key lies in creating workflows that scale with the team and codebase, minimizing friction in daily development.


