
How to Master Git Merging Strategies in Large Monorepos
Merge automation doesn’t just save CI cycles, it saves developer time, release velocity and engineering sanity.

How hard can merging be? There is a big green button you press and your changes are merged. That’s true for small engineering teams or those working in polyrepo setups. But in a large monorepo shared by dozens or hundreds of engineers, merging becomes one of the biggest bottlenecks in the software delivery pipeline.
Without going deep into a monorepo vs. polyrepo debate, let’s just say that monorepos have both benefits and challenges. On the benefits side, vulnerabilities are easily identified and fixed everywhere, easier refactoring, especially cross-project, standardization of tools and sharing the same libraries across different projects.
On the challenges side, there are:
- Stale dependencies: Pull requests (PRs) based on older mainline branches
- Implicit conflicts due to developers working on a similar code base
- Infrastructure issues (timeouts, etc.)
- Internal and third-party dependencies.
- Flaky tests: Shared state and inconsistent test behavior
And, as the engineering organization grows, the challenges increase exponentially. They may end up wasting hours of developers’ time just waiting for the builds to become green.

Merge Queues to the Rescue
Merge automation tools like GitHub Merge Queues, GitLab Merge Trains and Aviator Merge Queue change the game by introducing automation gates before merging to mainline.
How they work:
- A developer marks a PR as ready.
- The system rebases this PR onto the latest mainline.
- CI runs in this updated context.
- If CI passes, the system merges it.
- If new PRs arrive while CI runs, they wait for their turn.

How much time does that take?

Since we don’t have 50 hours in a day, let’s explore ways to optimize this process.
Batching PRs
Instead of merging one PR at a time, several of them are batched before running the continuous integration (CI) process. This merging strategy reduces the number of CI runs and shortens the waiting time for merges.
If the CI process for the batch succeeds, all pull requests in the batch are merged simultaneously, assuming that each ultimately passes the build. In case of a failure, the failing batches are bisected to identify which PR is causing the failure, and the rest are merged.
This method introduces some delays. To illustrate, under ideal conditions with no failures and a batch size of four, the total merge time decreases dramatically: from approximately 50 hours to about 12.5 hours.
In practical scenarios, failures occur. For instance, with a 10% failure rate, overall merge time can increase considerably, potentially extending to 24 hours for all pull requests to merge. Additionally, the total number of CI runs rises due to the repeated processing required to resolve failures.

Can we optimize the process further?
Optimistic Queues
Instead of thinking of merges happening in a serial world, let’s think of them as parallel universes. We don’t see mainline as a linear path, but as several potential futures that it can represent.
Rather than waiting for the initial CI process to complete, the system can optimistically assume the first pull request will pass. Based on this assumption, an alternate mainline branch is created to begin the CI process for the second pull request immediately. Once the CI for the first pull request completes successfully, it is merged into the mainline branch. Similarly, when the CI for the second pull request passes, it is also merged.

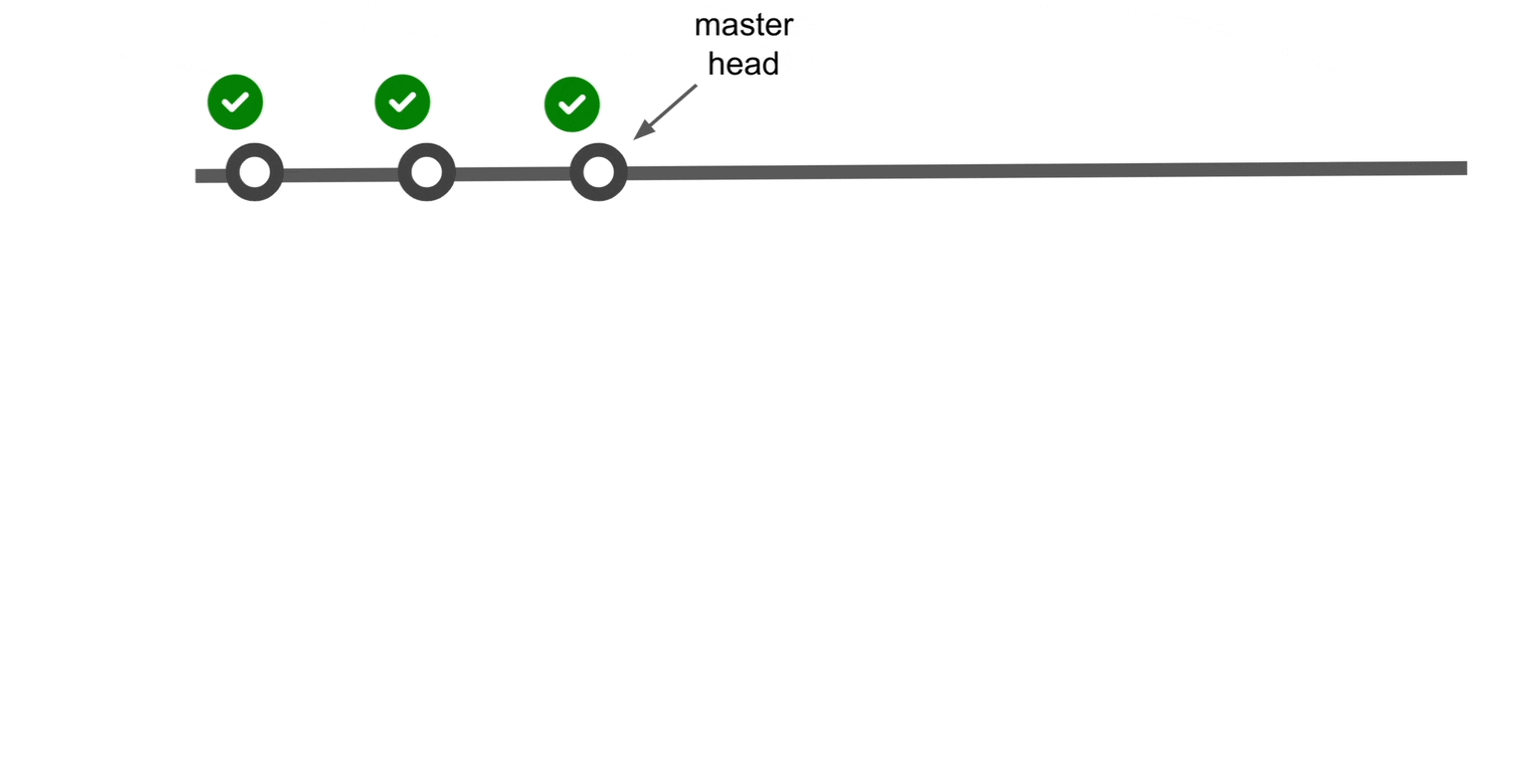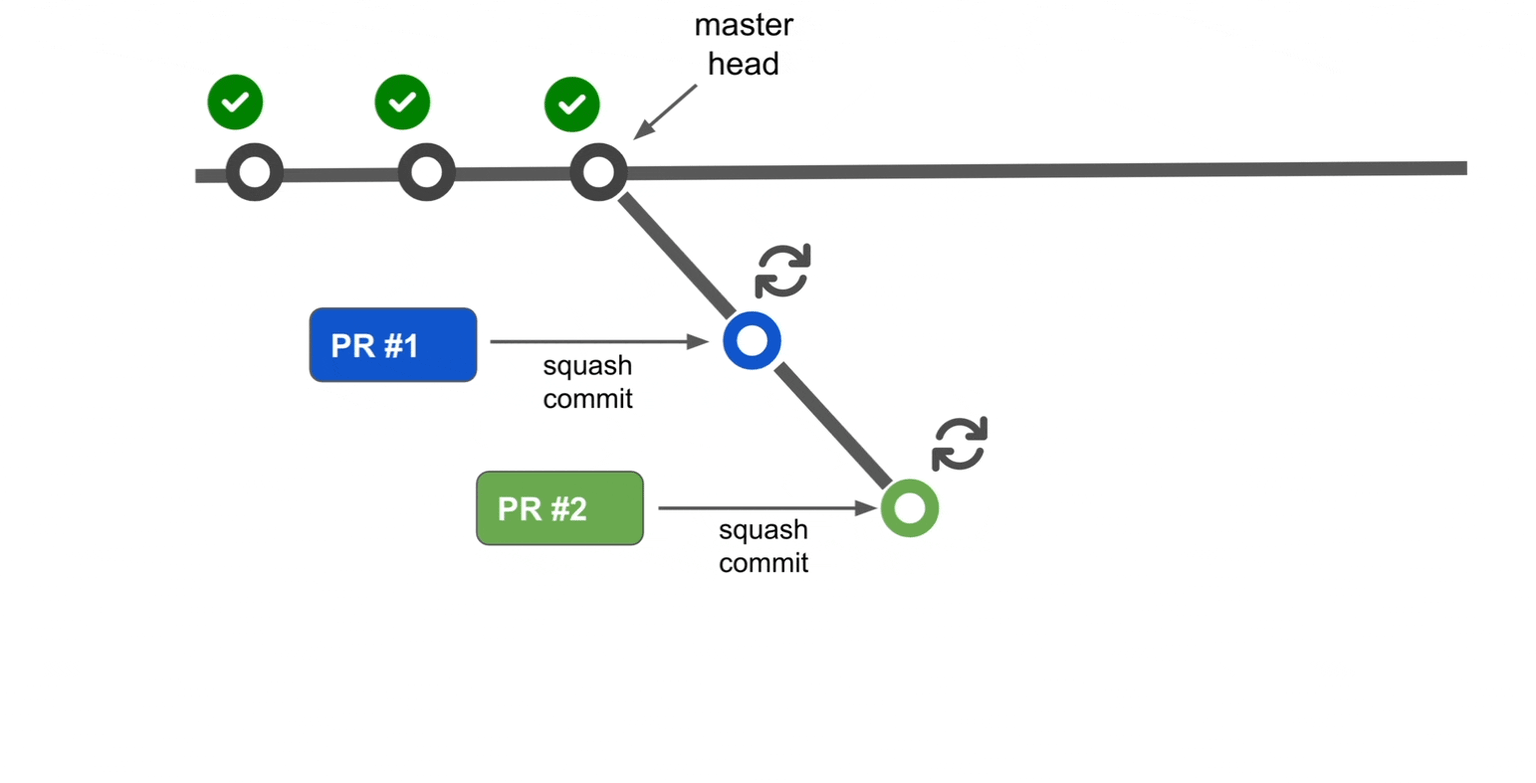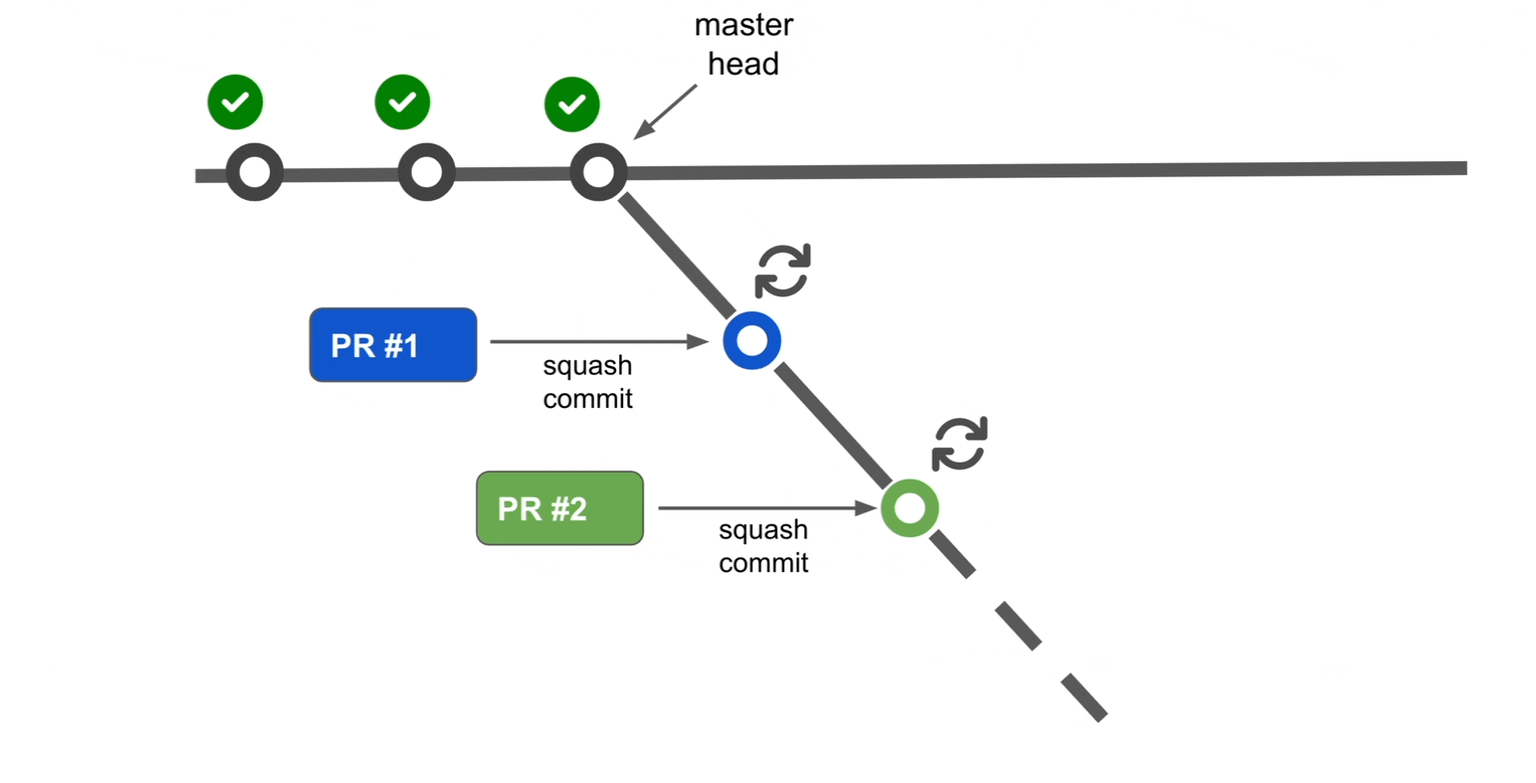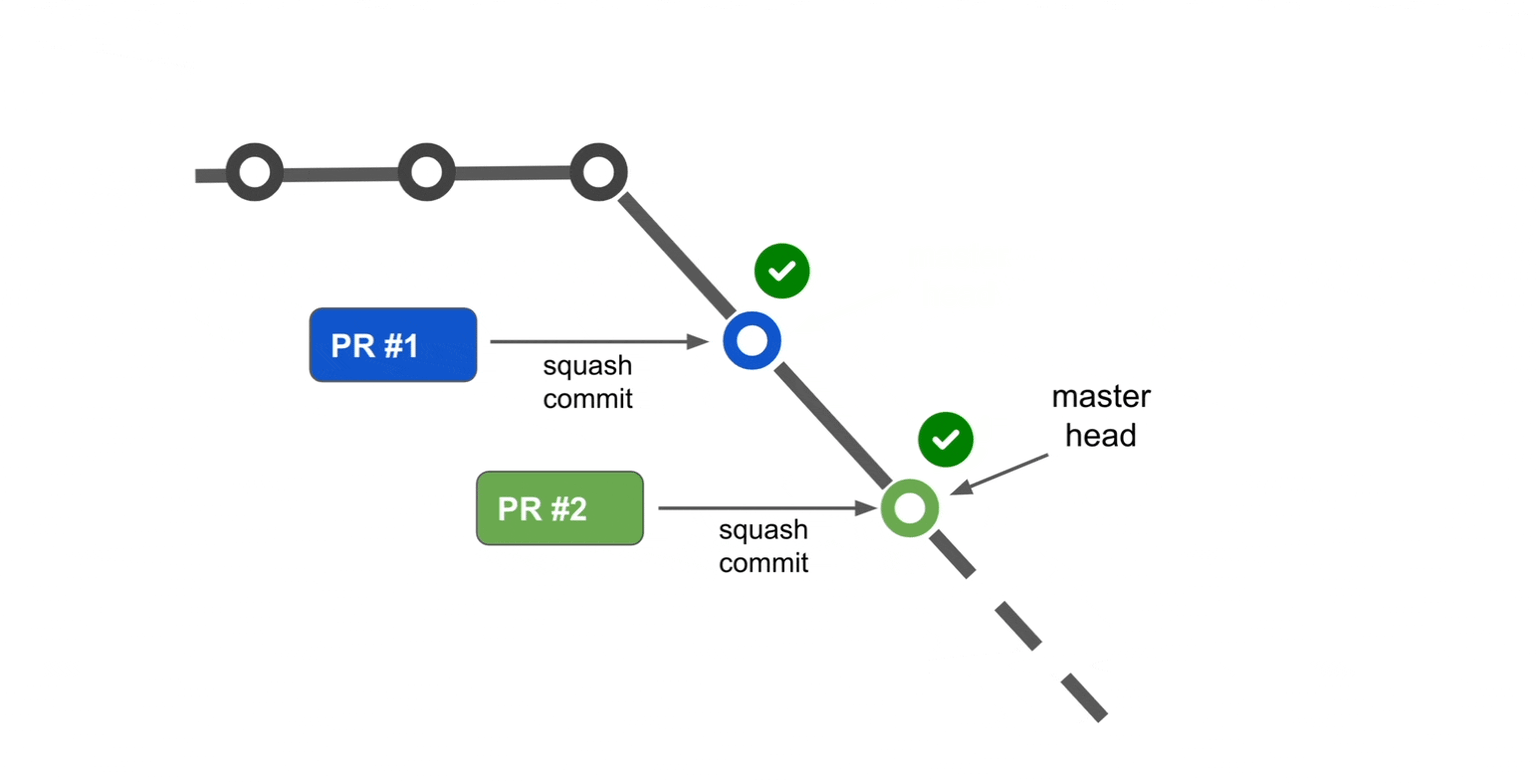
If the CI for the first one fails, the system will reject this alternate mainline and create a new alternate mainline without the first PR, run the validation and follow the same steps.
Let’s look at the numbers with optimistic queues:

Can we do better still?
Optimistic Batching
We’re combining the merging strategy of optimistic queues with batching, running a CI for batches of PRs and as they pass, they get merged. If they fail, they’re split up to identify what caused the failure.

Predictive Modeling
What if we could predict which PRs are likely to fail?
Instead of running CI on all possible combinations and scenarios for all of the PRs, we use predictive modeling. By calculating a score — based on lines of code and PR, types of files being modified, tests added or removed in a particular PR or a number of dependencies — we identify which paths are worth pursuing. This reduces CI cost but makes sure that the changes can be merged quickly.

Multi-Queues and Affected Targets
Instead of thinking of the process as a single queue, we can treat it as multiple independent paths or disjoint queues that run in parallel. This idea is based on the concept of affected targets.
Modern monorepo build tools like Bazel, Nx or Turborepo can identify which parts of the build are affected by a specific change. Using this information, we can group pull requests into separate queues, allowing builds that don’t affect each other to run concurrently.
Imagine a system that produces four different build types — A, B, C and D — and pull requests come in sequentially. Each PR might only involve some of these build types, so rather than waiting for one queue to process everything, we create separate queues for A, B, C and D and run them independently. This way, unrelated builds don’t block each other, speeding up the overall process.

More Merging Strategies to Optimize Workflows
Reordering Changes
Prioritizing pull requests with a lower risk of failure or deemed high priority by placing them earlier in the queue minimizes the likelihood of cascading failures and reduces the risk of a chain reaction of failures. Larger or more complex changes, which carry higher uncertainty, are scheduled later in the sequence.
Fail Fast
Reordering test execution prioritizes the tests most likely to fail to run first so failures can be detected early in the process. This ensures that problematic changes are identified and addressed quickly, reducing the number of possible failures.
Splitting Test Execution
Running a set of fast, critical tests before merging helps catch common issues early. More extensive or slower tests, such as smoke or integration tests, are run after the merge. These post-merge tests are expected to fail very rarely, and in such cases, an automated rollback mechanism can mitigate the risk.
Ultimately, the goal is to balance reliability with velocity, enabling teams to ship faster without compromising quality. Merge automation doesn’t just save CI cycles, it saves developer time, release velocity, and engineering sanity.
At Aviator, we care about developer experience and developer productivity. But we’re taking the anti-metrics approach to productivity. Instead of building shiny dashboards, we are building automated workflows across the entire software development life cycle: development, code reviews, builds, tests and deployments.
FAQs
What Is A 3 Way Merge Strategy?
A 3-way merge strategy in Git uses three snapshots: the common ancestor, the source branch, and the target branch. Git compares these versions to automatically merge changes, only asking for manual input when conflicts occur.
Which Merge Strategy Is Best?
The best Git merge strategy depends on your project. For small, simple updates, a fast-forward merge is clean and efficient. For collaborative projects or monorepos, a 3-way merge or squash merge is usually preferred to preserve history and maintain stability.
What Are The Different Types Of Merges In Git?
Git supports several merge strategies: fast-forward, 3-way merge, squash merge, rebase and merge, and octopus merges (for multiple branches). Each has trade-offs in terms of history clarity, conflict handling, and collaboration flow.
How To Git Merge Correctly?
To merge correctly, always pull the latest changes, test your branch locally, and resolve conflicts carefully. Use meaningful commit messages and choose a merge strategy that balances clean history with build stability.








